





PHÂN CỤM DỮ LIỆU
- Giới thiệu bài toán phân cụm
Bài toán
-
- Tập dữ liệu D = {di}
- Phân các dữ liệu thuộc D thành các cụm
- Các dữ liệu trong một cụm: “tương tự” nhau (gần nhau)
- Dữ liệu hai cụm: “không tương tự” nhau (xa nhau)
- Đo “tương tự” (gần) nhau ?
- Tiên đề phân cụm: Nếu người dùng lựa chọn một đối tượng d thì họ cũng lựa chọn các đối tượng cùng cụm với d
- Khai thác “cách chọn lựa” của người dùng
- Đưa ra một số độ đo “tương tự” theo biểu diễn dữ liệu
Một số nội dung liên quan
-
- Xây dựng độ đo tương tự
- Khai thác thông tin bổ sung
- Số lượng cụm cho trước, số lượng cụm không cho trước
Sơ bộ tiếp cận phân cụm
- Phân cụm mô hình và phân cụm phân vùng
- Mô hình: Kết quả là mô hình biểu diễn các cụm dữ liệu
- Vùng: Danh sách cụm và vùng dữ liệu thuộc cụm
- Phân cụm đơn định và phân cụm xác suất
- Đơn định: Mỗi dữ liệu thuộc duy nhất một cụm
- Xác suất: Danh sách cụm và xác suất một dữ liệu thuộc vào các cụm
- Phân cụm phẳng và phân cụm phân cấp
- Phẳng: Các cụm dữ liệu không giao nhau
- Phân cấp: Các cụm dữ liệu có quan hệ phân cấp cha- con
- Phân cụm theo lô và phân cụm tăng
- Lô: Tại thời điểm phân cụm, toàn bộ dữ liệu đã có
- Tăng: Dữ liệu tiếp tục được bổ sung trong quá trình phân cụm
Các phương pháp phân cụm
- Các phương pháp phổ biến
- Phân vùng, phân cấp, dựa theo mật độ, dựa theo lưới, dựa theo mô hình, và phân cụm mờ
- Phân cụm phân vùng (phân cụm phẳng)
- Xây dựng từng bước phân hoạch các cụm và đánh giá chúng theo các tiêu chí tương ứng
- Tiếp cận: từ dưới lên (gộp dần), từ trên xuống (chia dần)
- Độ đo tương tự / khoảng cách
- K-mean, k-mediod, CLARANS, …
- Hạn chế: Không điều chỉnh được lỗi
- Phân cụm phân cấp
- Xây dựng hợp (tách) dần các cụm tạo cấu trúc phân cấp và đánh giá theo các tiêu chí tương ứng
- Độ đo tương tự / khoảng cách
- HAC: Hierarchical agglomerative clustering
- CHAMELEON, BIRRCH và CURE, …
- Phân cụm dựa theo mật độ
- Hàm mật độ: Tìm các phần tử chính tại nơi có mật độ cao
- Hàm liên kết: Xác định cụm là lân cận phần tử chính
- DBSCAN, OPTICS…
- Phân cụm dựa theo lưới
- Sử dụng lưới các ô cùng cỡ: tuy nhiên cụm là các “ô” phân cấp
- Tạo phân cấp ô lưới theo một số tiêu chí: số lượng đối tượng trong ô
- STING, CLIQUE, WaweCluster…
- Phân cụm dựa theo mô hình
- Giải thiết: Tồn tại một số mô hình dữ liệu cho phân cụm
- Xác định mô hình tốt nhất phù hợp với dữ liệu
- MCLUST…
- Phân cụm mờ
- Giả thiết: không có phân cụm “cứng” cho dữ liệu và đối tượng có thể thuộc một số cụm
- Sử dụng hàm mờ từ các đối tượng tới các cụm
- FCM (Fuzzy CMEANS),…
- Một số độ đo cơ bản
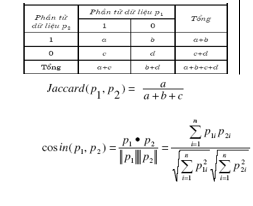
Độ đo tương đồng
-
- Biểu diễn: vector n chiều
- Giá trị nhị phân: Ma trận kề, độ đo Jaccard
- Giá trị rời rạc [0,m]: Chuyển m giá trị thành nhị phân, độ đo Jaccard
- Giá trị thực : độ đo cosin hai vector

Độ đo khác biệt
-
- Đối ngẫu độ đo tương đồng
- Thuộc tính nhị phân: đối cứng, không đối xứng
- Giá trị rời rạc: hoặc tương tự trên hoặc dạng đơn giản (q thuộc tính giống nhau)
- Giá trị thực: Khoảng cách Manhattan, Euclide, Mincowski
- Tính xác định dương, tính đối xứng, tính bất đẳng thức tam giác

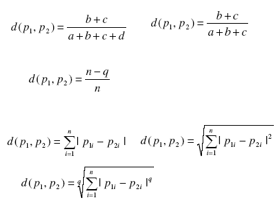
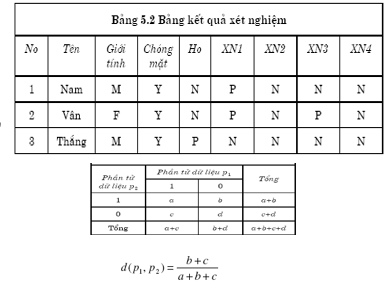
Ví dụ về độ khác biệt
-
- CSDL xét nghiệm bệnh nhân
- Quy về giá trị nhị phân: M/F, Y/N, N/P
- Lập ma trận khác biệt cho từng cặp đối tượng.
- Ví dụ, cặp (Nam, Vân): a=2, b=1, c=1, d=3
D(Nam, Vân) =(1+1)/(2+1+1)=0.5

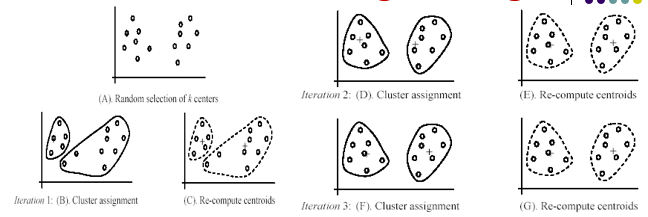
- Thuât toán K-mean gán cứng


Một số lưu ý
-
- Điều kiện dừng
- Sau bước 2 không có sự thay đổi cụm
- Điều kiện dừng cưỡng bức
- Khống chế số lần lặp
- Giá trị mục tiêu đủ nhỏ
- Vấn đề chọn tập đại diện ban đầu ở bước Khởi động
- Có thể dùng độ đo khoảng cách thay cho độ đo tương tự
- Điều kiện dừng
- Thuât toán K-mean gán cứng

- Một số lưu ý (tiếp) và ví dụ
- Trong bước 2: các trọng tâm có thể không thuộc S
- Thực tế: số lần lặp £ 50
- Thi hành k-mean với dữ liệu trên đĩa
- Toàn bộ dữ liệu quá lớn: không thể ở bộ nhớ trong
- Với mỗi vòng lặp: duyệt CSDL trên đĩa 1 lần
- Tính được độ tương tự của d với các ci.
- Tính lại ci mới: bước 2.1 khởi động (tổng, bộ đếm); bước 2.2 cộng và tăng bộ đếm; bước 2.3 chỉ thực hiện k phép chia.
Thuât toán K-mean mềm
- Input
- Số nguyên k > 0: số cụm biết trước
- Tập dữ liệu D (cho trước)
- Output
- Tập k “đại diện cụm” mC làm cực tiểu lỗi “lượng tử”

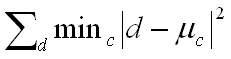
- Tập k “đại diện cụm” mC làm cực tiểu lỗi “lượng tử”
- Định hướng
- Tinh chỉnh mC dần với tỷ lệ học h (learning rate)

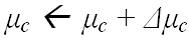
- Tinh chỉnh mC dần với tỷ lệ học h (learning rate)

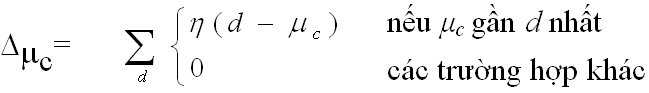

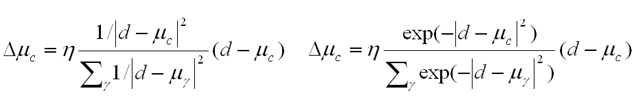
- Ưu điểm
- Đơn giản, dễ sử dụng
- Hiệu quả về thời gian: tuyến tính O(tkn), t số lần lặp, k số cụm, n là số phần tử
- Một thuật toán phân cụm phổ biến nhất
- Thường cho tối ưu cục bộ. Tối ưu toàn cục rất khó tìm
- Nhược điểm
- Phải “tính trung bình được”: dữ liệu phân lớp thì dựa theo tần số
- Cần cho trước k : số cụm
- Nhạy cảm với ngoại lệ (cách xa so với đại đa số dữ liệu còn lại): ngoại lệ thực tế, ngoại lệ do quan sát sai (làm sạch dữ liệu)
- Nhạy cảm với mẫu ban đầu: cần phương pháp chọn mẫu thô tốt
- Không thích hợp với các tập dữ liệu không siêu-ellip hoặc siêu cầu (các thành phần con không ellip/cầu hóa)
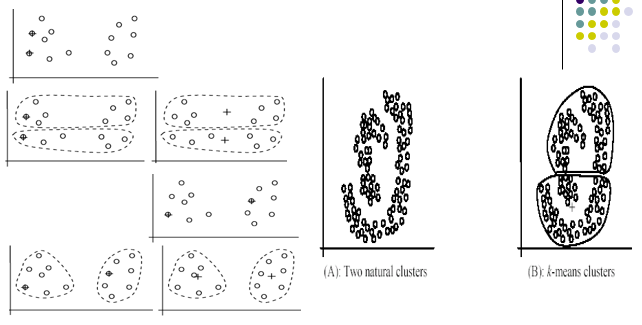

Trái: Nhạy cảm với chọn mẫu ban đầu
Phải: Không thích hợp với bộ dữ liệu không siêu ellip/cầu hóa
-
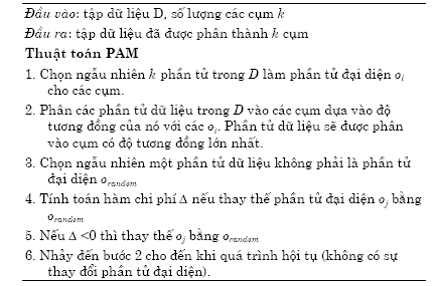
- Thuât toán PAM (K-mediod)
-
- K-mediod
- Biến thể của K-mean: thay trọng tâm bằng một phần tử của D
- Hàm mục tiêu
- PAM: Partition Around Mediods
- K-mediod

- Phân cụm phân cấp
- HAC: Hierarchical agglomerative clustering
- Một số độ đo phân biệt cụm
- Độ tương tự hai tài liệu
- Độ tương tư giữa hai cụm
- Độ tương tự giữa hai đại diện
- Độ tương tự cực đại giữa hai dữ liệu thuộc hai cụm: single-link
- Độ tương tự cực tiểu giữa hai dữ liệu thuộc hai cum: complete-link
- Độ tương tự trung bình giữa hai dữ liệu thuộc hai cum
- Sơ bộ về thuật toán
- Đặc điểm: Không cho trước số lượng cụm k, cho phép đưa ra các phương án phân cụm theo các giá trị k khác nhau
- Lưu ý: k là một tham số ð “tìm k tốt nhất”
- Tinh chỉnh: Từ cụ thể tới khái quát
- Phân cụm phân cấp từ dưới lên


- Giải thích
- G là tập các cụm trong phân cụm
- Điều kiện |G| < k có thể thay thế bằng |G|=1
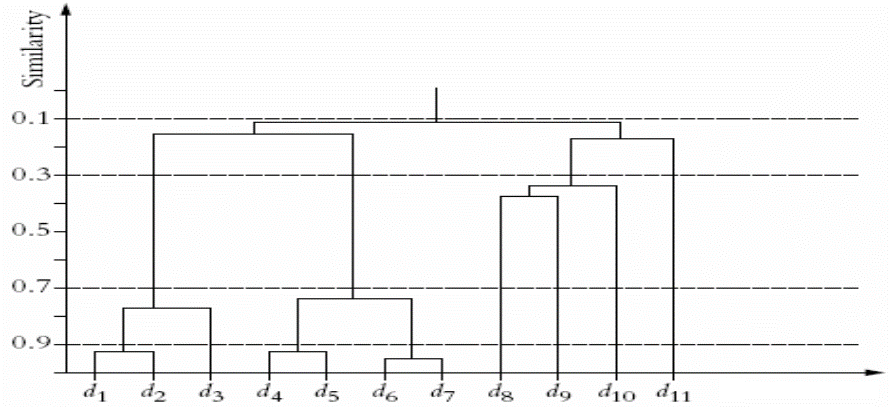

- Hoạt động HAC
- Cho phép với mọi k
- Chọn phân cụm theo “ngưỡng” về độ tương tự
HAC với các độ đo khác nhau

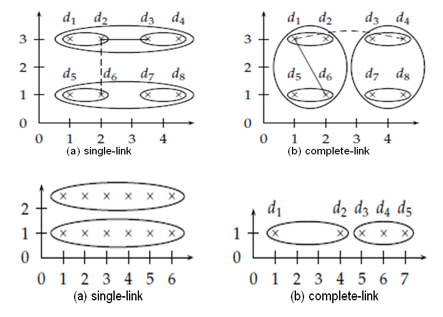
- Ảnh hưởng của các độ đo
- Trên: Hoạt động thuật toán khác nhau theo các độ đo khác nhau: độ tương tự cực tiểu (complete-link) có tính cầu hơn so với cực đại
- Dưới: Độ tương tự cực đại (Single-link) tạo cụm chuỗi dòng
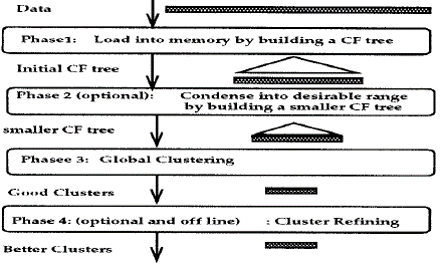
- Phân cụm phân cấp BIRCH
- Balanced Iterative Reducing Clustering Using Hierarchies
- Tính khả cỡ: Làm việc với tập dữ liệu lớn
- Tính bất động: Gán không đổi đối tượng –> cụm
- Khái niệm liên quan
- Đặc trưng phân cụm CF: tóm tắt của cụm
- CF = <n, LS, SS>, n: số phần tử, LS: vector tổng các thành phần dữ liêu; SS : vector tổng bình phương các thành phần các đối tượng
- <3, (9,10), (29,38)>. Khi ghép cụm không tính lại các tổng
- Cây đặc trưng phân cụm CF Tree
- Một cây cân bằng
- Hai tham số: bề rộng b và ngưỡng t
- Thuật toán xây dựng cây
- Đặc trưng phân cụm CF: tóm tắt của cụm
BIRCH: Năm độ đo khoảng cách
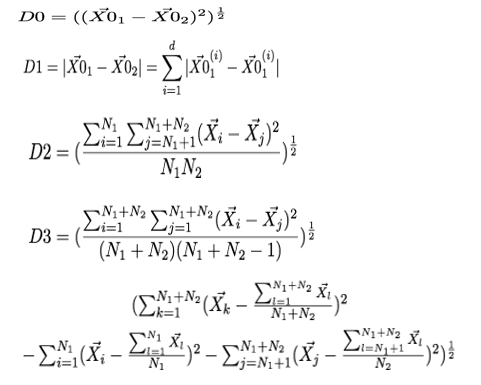

Cây đặc trưng phân cụm CF Tree
- Mỗi nút không là lá có nhiều nhất là B cành
- Mỗi nút lá có nhiều nhất L đặc trưng phân cụm mà đảm bảo ngưỡng T
- Cỡ của nút được xác định bằng số chiều không gian dữ liệu và tham số P kích thước trang bộ nhớ

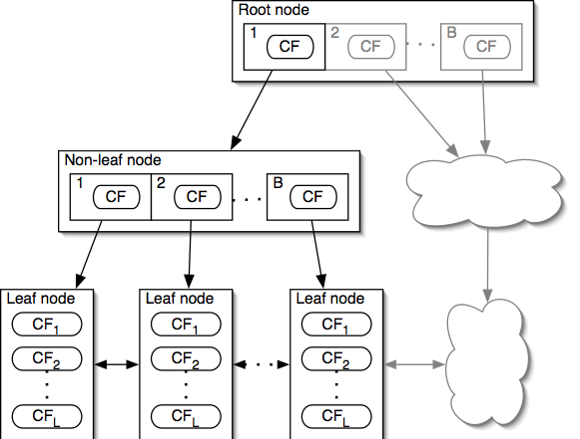
Chèn vào CF Tree và BIRCH
- Cây ban đầu rỗng
- Chèn một “cụm” a vào cây
- Xác định lá thích hợp: Duyệt từ gốc xuống một cách đệ quy để tới nút con gần a nhất theo 1 trong 5 khoảng cách nói trên
- Biến đổi lá: Nếu gặp lá L1 gần a nhất, kiểm tra xem L1 có “hấp thụ“ a không (chưa vượt ngưỡng); nếu có thì đặc trưng CF của L1 bổ sung; Nếu không, tạo nút mới cho a; nếu không đủ bộ nhớ cho lá mới thì cần chia lá cũ
- Biến đổi đường đi tới lá khi bổ sung phần tử mới
- Tinh chỉnh việc trộn:

Các thuật toán phân cụm khác
- Phân cụm phân cấp từ trên xuống DIANA
- Đối ngẫu phân cụm phân cấp từ trên xuống: phần tử khác biệt -> cụm khác biệt S,
- Thêm vào S các phần tử có d > 0
- Phân cụm phân cấp ROCK
- RObust Clustering using linKs: xử lý dữ liệu rời rạc, quyết định “gần” theo tập phần tử láng giềng sim (p, q) > q>0.
- Phân cụm dựa trên mật độ DBSCAN
- Density-Based Spatial Clustering of Application with Noise
- #-neighborhood: vùng lân cận bán kính #
- | #-neighborhood| > MinPts gọi đối tượng lõi
- P đạt được trực tiếp theo mật độ từ q nếu q là đối tượng lõi và p thuộc #-neighborhood của q.
- Đạt được nếu có dãy mà mỗi cái sau là đạt được trực tiếp từ cái trước
- Phân cụm phân cấp dựa trên mô hình
- Làm phù hợp phân bố cụm với mô hình toán học
- Phân cụm cực đại kỳ vọng, phân cụm khái niệm, học máy mạng nơron
- Phân cụm cực đại kỳ vọng: khởi tạo, tính giá trị kỳ vọng, cực đại hóa kỳ vọng
7. Biểu diễn cụm và gán nhãn
- Các phương pháp biểu diễn điển dình
- Theo đại diện cụm
- Đại diện cụm làm tâm
- Tính bán kính và độ lệch chuẩn để xác định phạm vi của cụm
- Cụm không ellip/cầu hóa: không tốt
- Theo mô hình phân lớp
- Chỉ số cụm như nhãn lớp
- Chạy thuật toán phân lớp để tìm ra biểu diễn cụm
- Theo mô hình tần số
- Dùng cho dữ liệu phân loại
- Tần số xuất hiện các giá trị đặc trưng cho từng cụm
- Theo đại diện cụm
- Lưu ý
- Dữ liệu phân cụm ellip/cầu hóa: đại diện cụm cho biểu diễn tốt
- Cụm hình dạng bất thường rất khó biểu diễn
Gán nhãn cụm
- Phân biệt các cụm (MU)

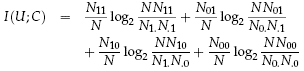
- Chọn đặc trưng tương quan cụm
- Nxy (x có đặc trưng t, y dữ liệu thuộc C)
- N11 : số dữ liệu chứa t thuộc cụm C
- N10 : số dữ liệu chứa t không thuộc cụm C
- N01 : số dữ liệu không chứa t thuộc cụm C
- N00 : số dữ liệu không chứa t không thuộc cụm C
- N: Tổng số dữ liệu
- Hướng “trọng tâm” cụm
- Dùng các đặc trưng tần số cao tại trọng tâm cụm
- Tiêu đề
- Chon đặc trưng của dữ liệu trong cụm gần trọng tâm nhất
Ví dụ: Gán nhãn cụm văn bản

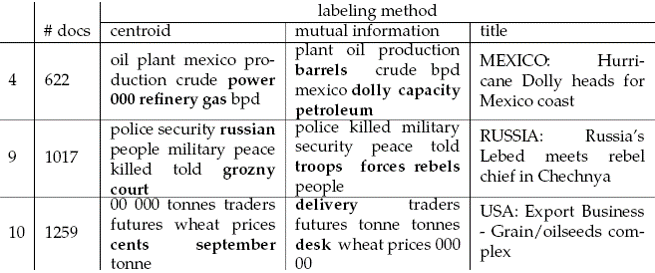
- Ví dụ
- Ba phương pháp chọn nhãn cụm đối với 3 cụm là cụm 4 (622 tài liệu), cụm 9 (1017 tài liệu), cụm 10 (1259 tài liệu) khi phân cụm 10000 tài liệu đầu tiên của bộ Reuters-RCV1
- centroid: các từ khóa có tần số cao nhất trong trọng tâm; mutual information (MU): thông tin liên quan phân biệt các cụm; title: tiêu đề tài liệu gần trọng tâm nhất.
8. Đánh giá phân cụm
Đánh giá chất lượng phân cụm là khó khăn
-
- Chưa biết các cụm thực sự
- Một số phương pháp điển hình
- Người dùng kiểm tra
- Nghiên cứu trọng tâm và miền phủ
- Luật từ cây quyết định
- Đọc các dữ liệu trong cụm
- Đánh giá theo các độ đo tương tự/khoảng cách
- Độ phân biệt giữa các cụm
- Phân ly theo trọng tâm
- Dùng thuật toán phân lớp
- Coi mỗi cụm là một lớp
- Học bộ phân lớp đa lớp (cụm)
- Xây dựng ma trận nhầm lẫn khi phân lớp
- Tính các độ đo: entropy, tinh khiết, chính xác, hồi tưởng, độ đo F và đánh giá theo các độ đo này
- Người dùng kiểm tra
Đánh giá theo độ đo tương tự
- Độ phân biệt các cụm
- Cực đại hóa tổng độ tương tự nội tại của các cụm
- Cực tiểu hóa tổng độ tương tự các cặp cụm khác nhau
- Lấy độ tương tự cực tiểu (complete link), cực đại (single link)

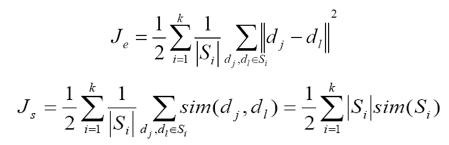
- Một số phương pháp điển hình
- Phân ly theo trọng tâm

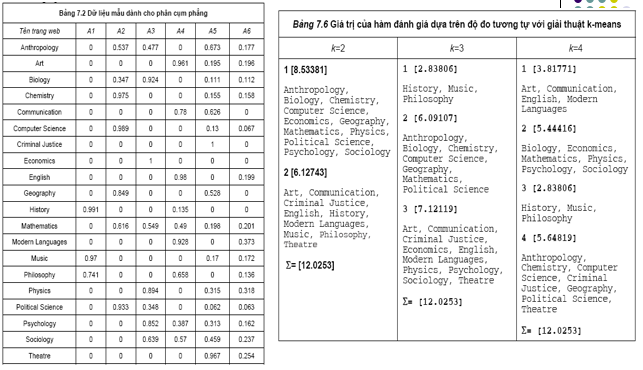
Ví dụ: Chế độ và đặc điểm phân cụm web
- Hai chế độ
- Trực tuyến: phân cụm kết quả tìm kiếm người dùng
- Ngoại tuyến: phân cụm tập văn bản cho trước
- Đặc điểm
- Chế độ trực tuyến: tốc độ phân cụm
- Web số lượng lớn, tăng nhanh và biến động lớn
- Quan tâm tới phương pháp gia tăng
- Một lớp quan trọng: phân cụm liên quan tới câu hỏi tìm kiếm
- Trực tuyến
- Ngoại tuyến
- Chế độ trực tuyến: tốc độ phân cụm
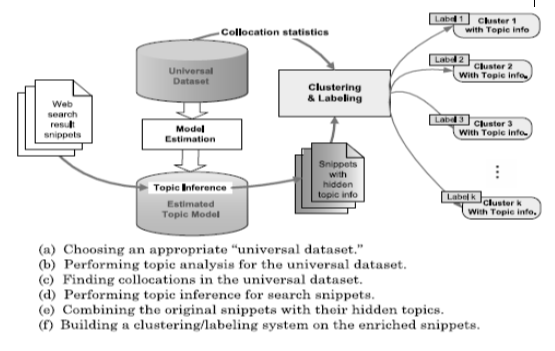
Ví dụ

Phân cụm kết quả tìm kiếm

Bài viết nổi bật


30+ Các câu hỏi phỏng vấn Fresher Java
27/12/2023



Bài viết nổi bật
30+ Các câu hỏi phỏng vấn Fresher Java
27/12/2023