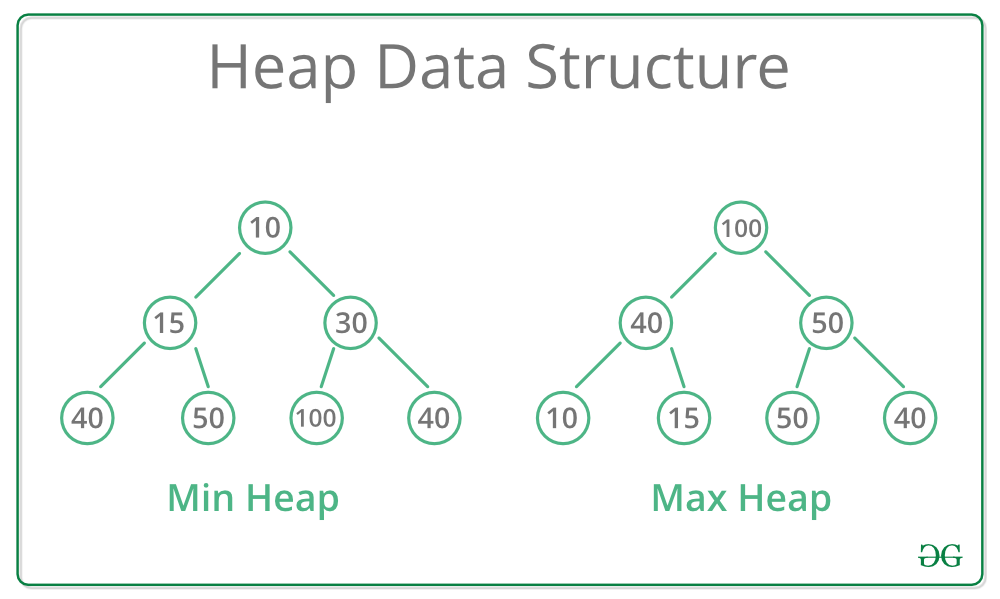
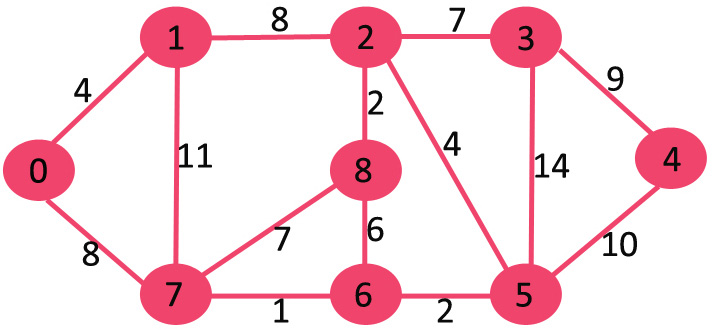
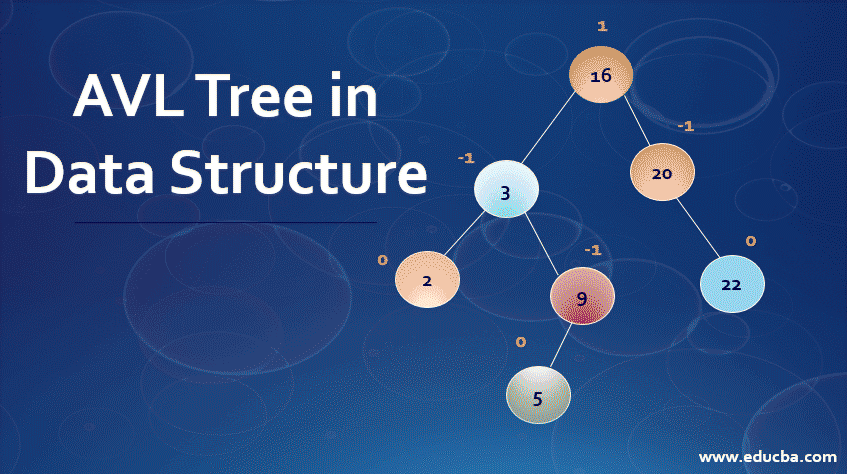
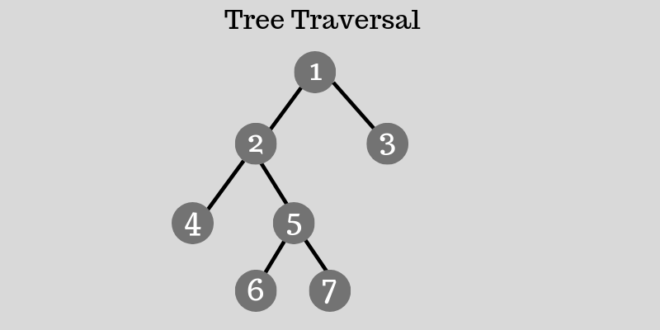
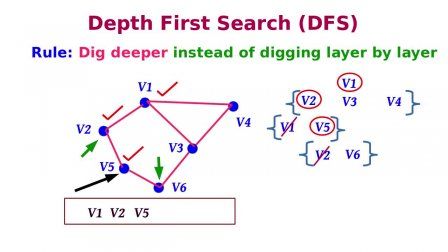
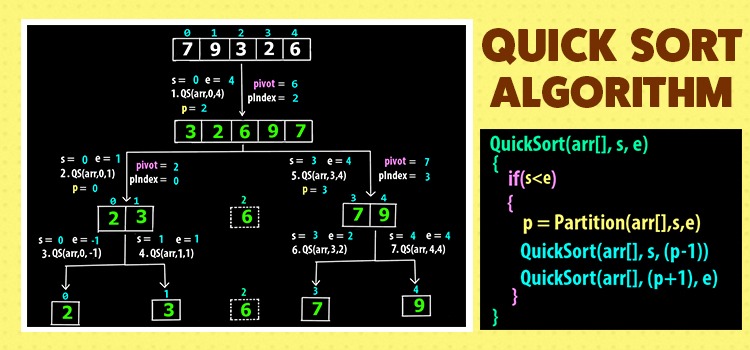
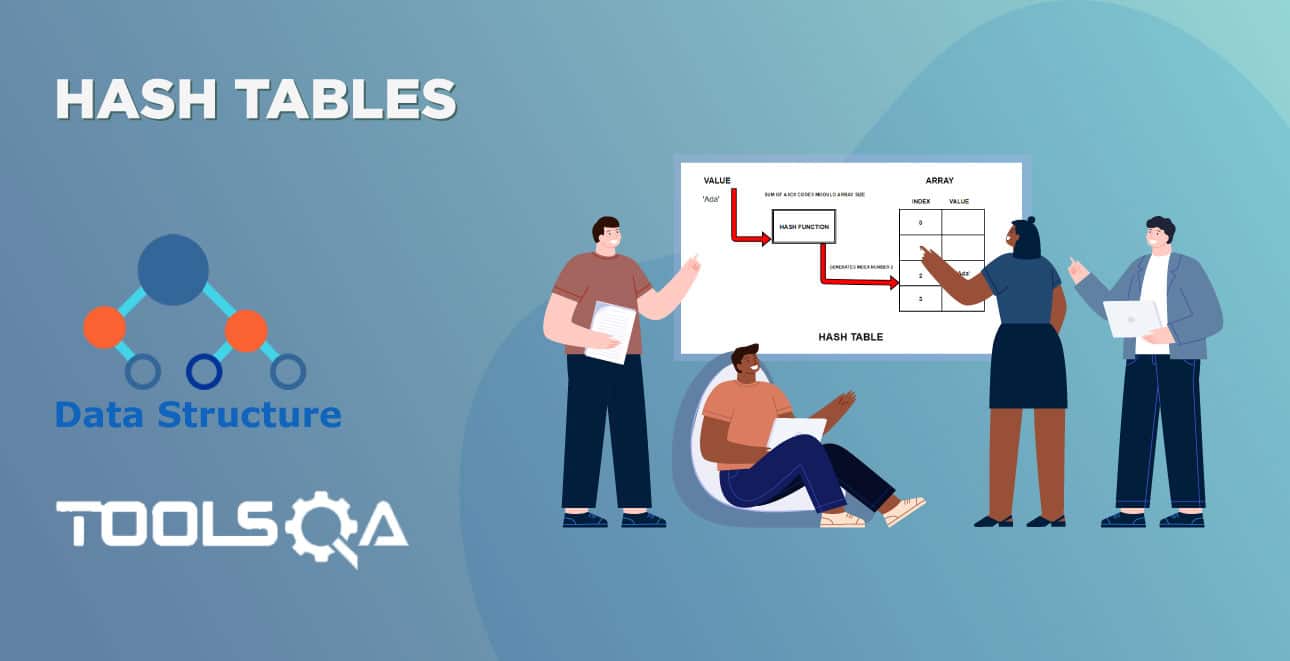
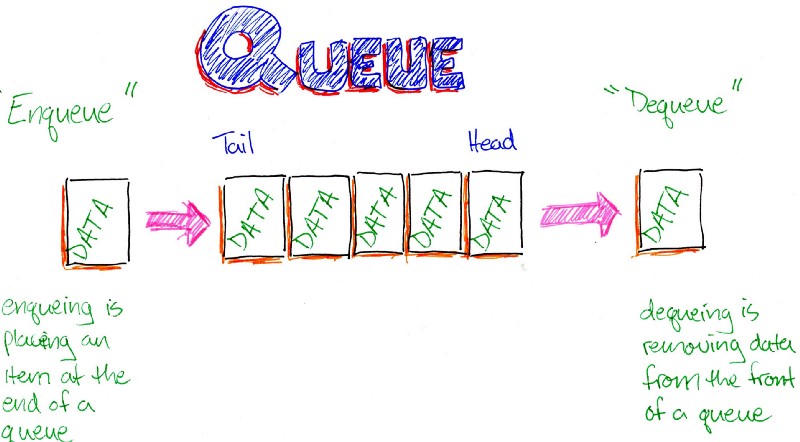
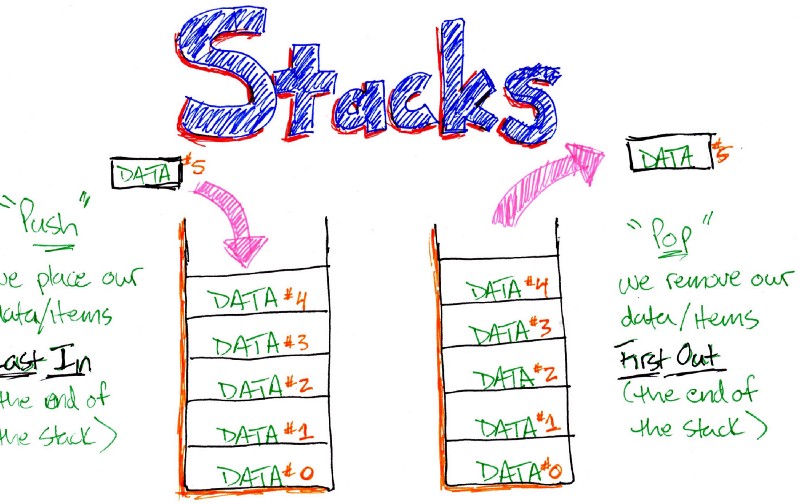
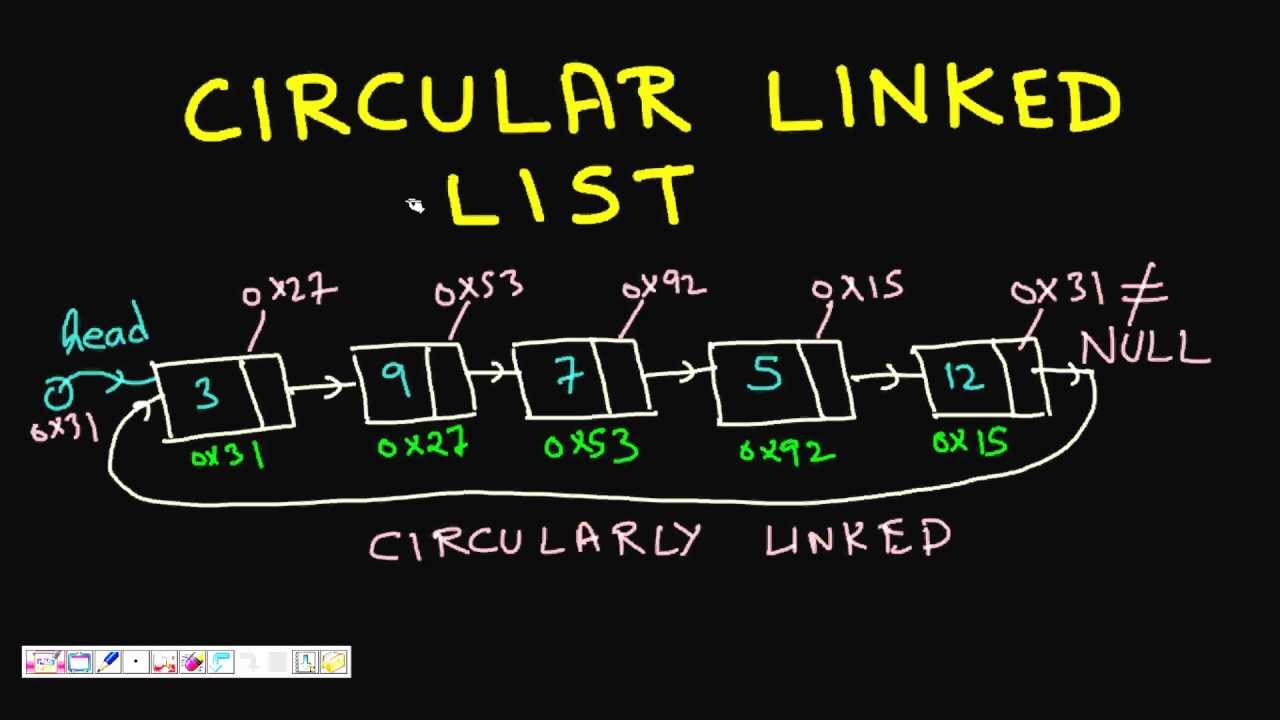
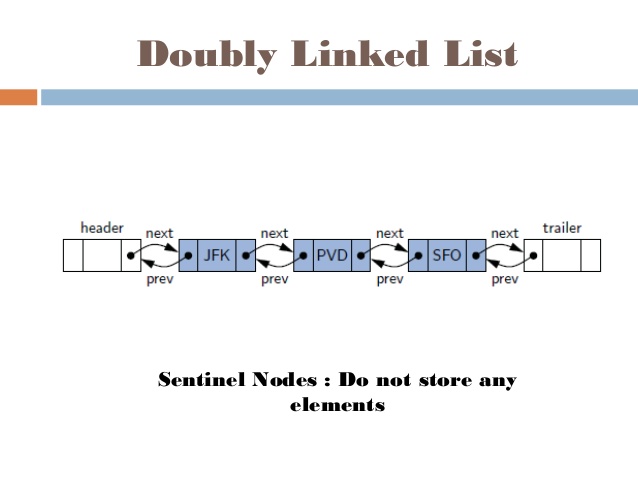
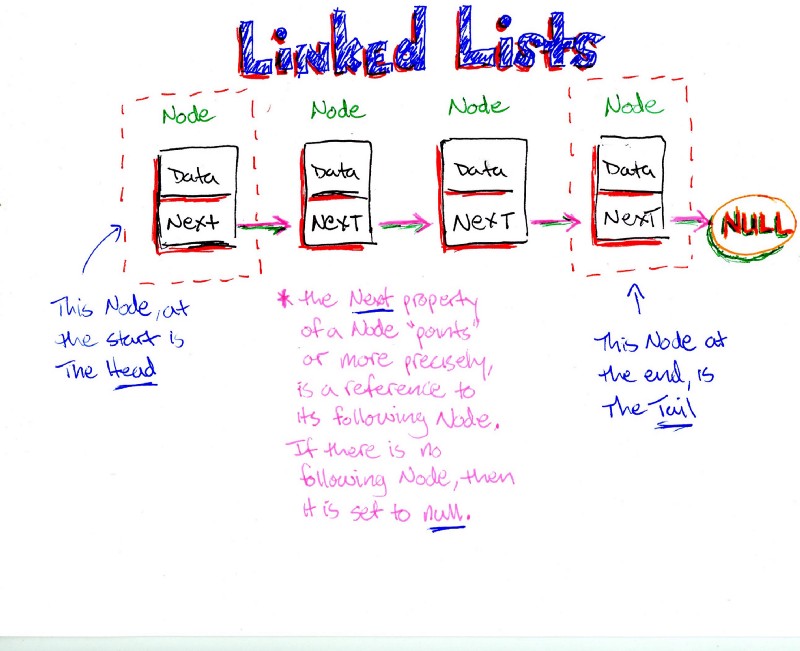
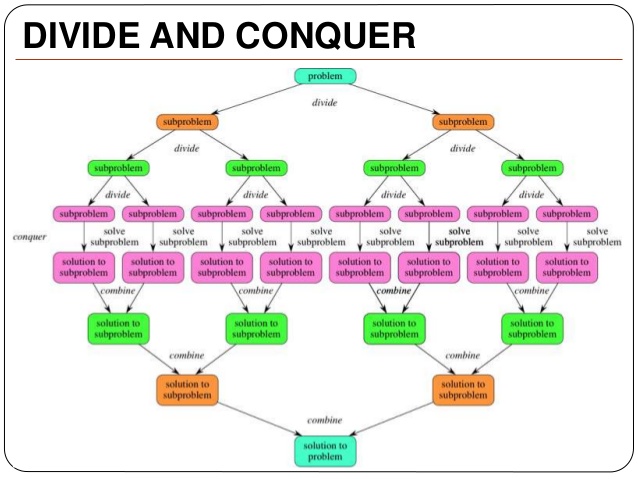
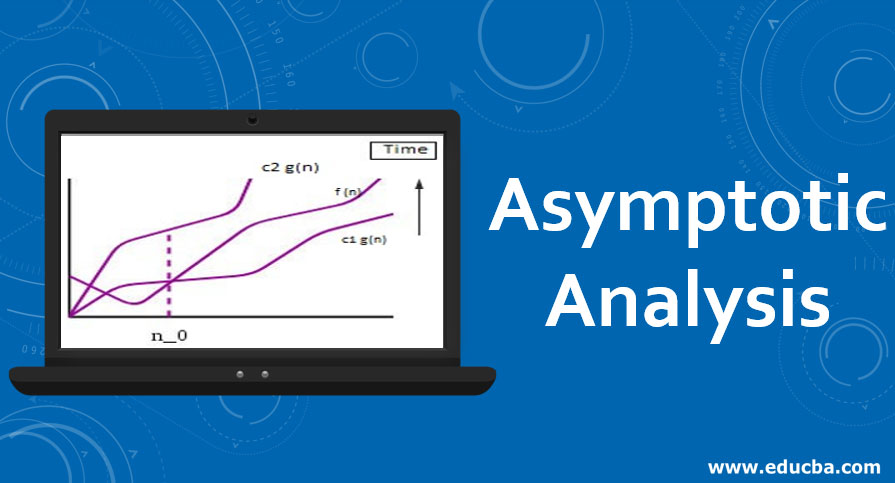
Một thuật toán được thiết kế để đạt được giải pháp tối ưu cho một vấn đề nhất định. Theo cách tiếp cận thuật toán tham lam, các quyết định được đưa ra từ miền giải pháp đã cho. Vì tham lam, giải pháp gần nhất có vẻ cung cấp giải pháp tối ưu được chọn. Các thuật toán tham lam cố gắng tìm một giải pháp tối ưu cục bộ, cuối cùng có thể dẫn đến các giải pháp tối ưu hóa toàn cầu. Tuy nhiên, nhìn chung các thuật toán tham lam không cung cấp các giải pháp tối ưu hóa toàn cầu.