





Giới thiệu
- Máy vectơ hỗ trợ (Support vector machine - SVM) được đề cử bởi V. Vapnik và các đồng nghiệp của ông vào những năm 1970s ở Nga, và sau đó đã trở nên nổi tiếng và phổ biến vào những năm 1990s
- SVM là một phương pháp phân lớp tuyến tính (linear classifier), với mục đích xác định một siêu phẳng (hyperplane) để phân tách hai lớp của dữ liệu.
Ví dụ: lớp có nhãn dương (positive) và lớp có nhãn âm (negative)
- Các hàm nhân (kernel functions), cũng được gọi là các hàm biến đổi (transformation functions), được dùng cho các trường hợp phân lớp phi tuyến
- SVM có một nền tảng lý thuyết chặt chẽ
- SVM là một phương pháp tốt (phù hợp) đối với những bài toán phân lớp có không gian rất nhiều chiều (các đối tượng cần phân lớp được biểu diễn bởi một tập rất lớn các thuộc tính)
- SVM đã được biết đến là một trong số các phương pháp phân lớp tốt nhất đối với các bài toán phân lớp văn bản (text classification)
- Các vectơ được ký hiệu bởi các chữ đậm nét!
- Biểu diễn tập r các quan sát: {(x1, y1), (x2, y2), …, (xr, yr)},
- xi là một vectơ đầu vào được biểu diễn trong không gian X Í Rn
- yi là một nhãn lớp (giá trị đầu ra), yi Î {1,-1}
- yi=1: lớp dương (positive); yi=-1: lớp âm (negative)
- SVM xác định một hàm phân tách tuyến tính: f(x) = <w × x> + b
- w là vectơ trọng số các thuộc tính; b là một giá trị số thực
- Sao cho với mỗi xi:

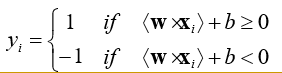
Siêu phẳng phân tách
- Siêu phẳng phân tách các quan sát thuộc lớp dương và các quan sát thuộc lớp âm: <w × x> + b = 0
- Còn được gọi là ranh giới (bề mặt) quyết định
- Tồn tại nhiều siêu phẳng phân tách. Chọn cái nào?

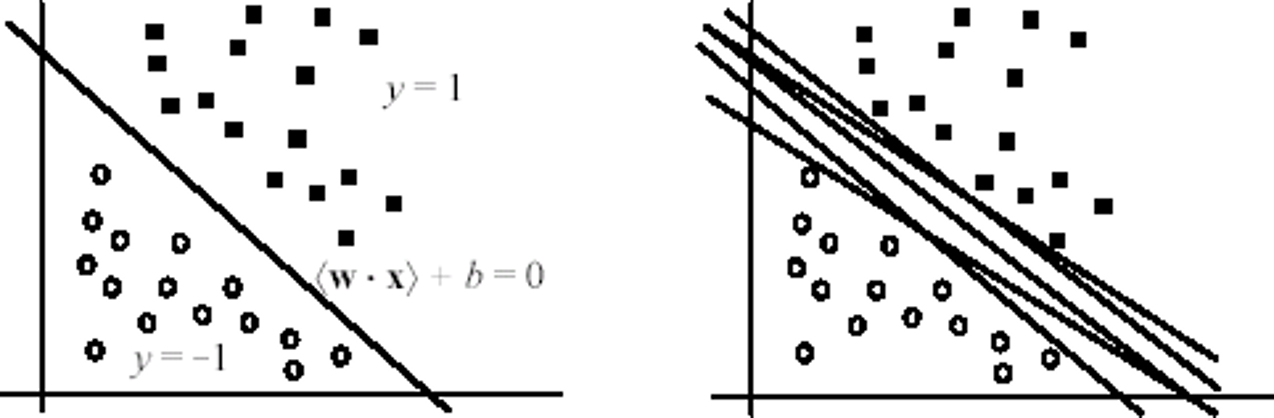
Mặt siêu phẳng có lề cực đại
- SVM lựa chọn mặt siêu phẳng phân tách có lề (margin) lớn nhất
- Lý thuyết học máy đã chỉ ra rằng một mặt siêu phẳng phân tách như thế sẽ tối thiểu hóa giới hạn lỗi (phân lớp) mắc phải (so với mọi siêu phẳng khác)

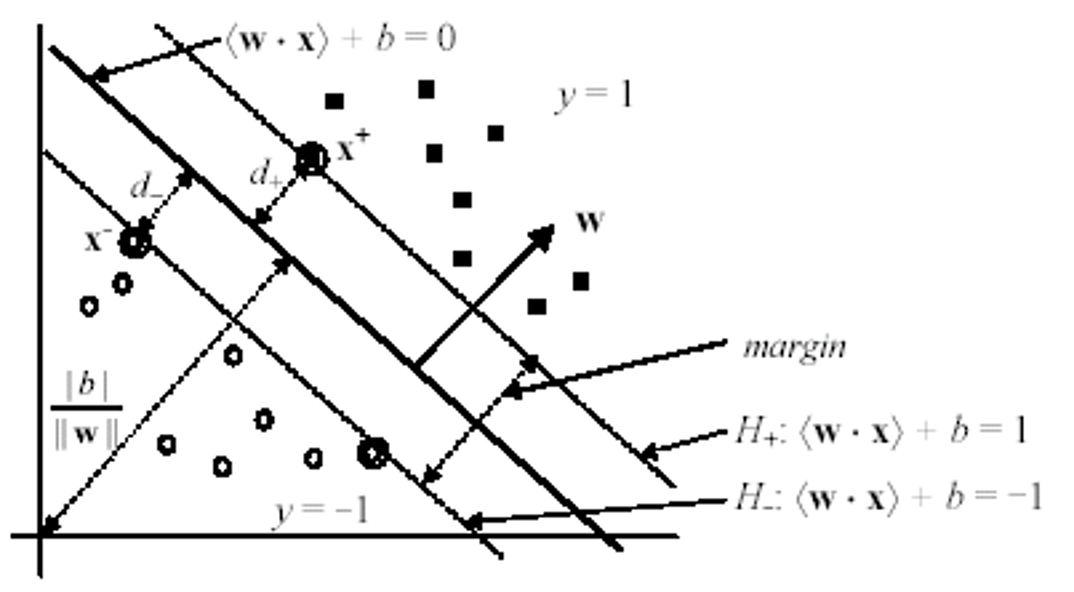
Phân tách tuyến tính (linear separability)
- Giả sử rằng tập dữ liệu huấn luyện có thể phân tách được một cách tuyến tính
- Xét một quan sát của lớp dương (x+,1) và một quan sát của lớp âm (x-,-1) gần nhất đối với siêu phẳng phân tách H0 (< 𝒘, 𝒙 > +𝑏 = 0)
- Định nghĩa 2 siêu phẳng lề song song với nhau
- H+ đi qua x+, và song song với H0
- H- đi qua x-, và song song với H0

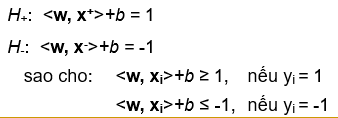
Tính toán mức lề
- Mức lề (margin) là khoảng cách giữa 2 siêu phẳng lề H+
- và H-. Trong hình vẽ nêu trên:
- d+ là khoảng cách giữa H+ và H0
- d- là khoảng cách giữa H- và H0
- (d+ + d-) là mức lề
- Trong không gian vectơ, khoảng cách từ một điểm xi đến siêu phẳng (<w × x> + b = 0) là:

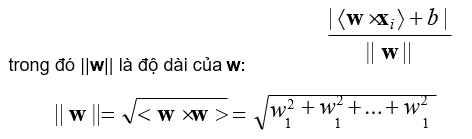
- Tính toán d+: khoảng cách từ x+ đến (<w × x> + b = 0)
- Áp dụng các biểu thức
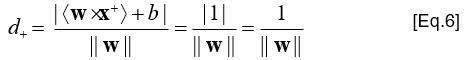

- Tính toán d-: khoảng cách từ x- đến (<w × x> + b = 0)
- Áp dụng các biểu thức

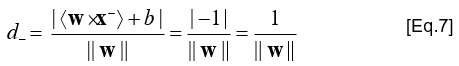
- Tính toán mức lề

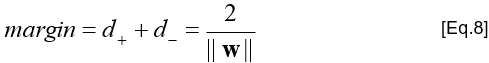
Học SVM: cực đại hóa mức lề
Định nghĩa (Linear SVM – Trường hợp phân tách được)
- Tập gồm r ví dụ huấn luyện có thể phân tách tuyến tính D = {(x1,y1), (x2,y2), …, (xr,yr)}
- SVM học một phân lớp (classifier) mà có mức lề cực đại
- Tương đương với việc giải quyết bài toán tối ưu bậc hai sau đây
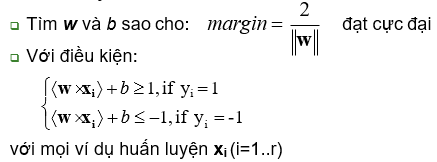

- Học SVM tương đương với giải quyết bài toán cực tiểu hóa có ràng buộc sau đây

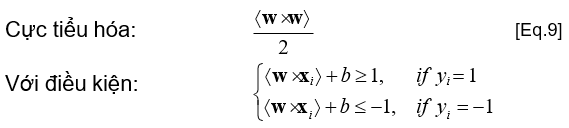
- Tương đương với

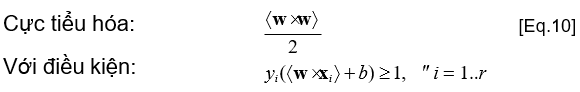
Lý thuyết tối ưu có ràng buộc
- Bài toán cực tiểu hóa có ràng buộc đẳng thức: Cực tiểu hóa f(x), với điều kiện g(x)=0
- Điều kiện cần để x0 là một lời giải:

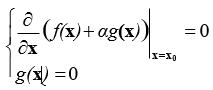
với a là một hệ số nhân (multiplier) Lagrange
- Trong trường hợp có nhiều ràng buộc đẳng thức gi(x)=0 (i=1..r), cần một hệ số nhân Lagrange cho mỗi ràng buộc:

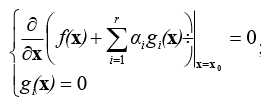
- Bài toán cực tiểu hóa có các ràng buộc bất đẳng thức: Cực tiểu hóa f(x), với các điều kiện gi(x)≤0
- Điều kiện cần để x0 là một lời giải:

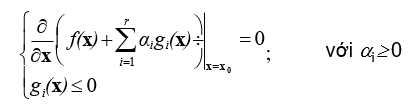
- Hàm


Học SVM: giải bài toán cực tiểu hóa
- Biểu thức Lagrange

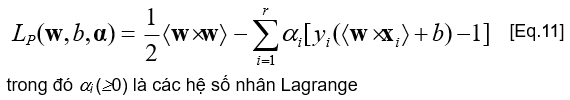
- Lý thuyết tối ưu chỉ ra rằng một lời giải tối ưu cho [Eq.11] phải thỏa mãn các điều kiện nhất định, được gọi là các điều kiện Karush-Kuhn-Tucker (là các điều kiện cần, nhưng không phải là các điều kiện đủ)
- Các điều kiện Karush-Kuhn-Tucker đóng vai trò trung tâm trong cả lý thuyết và ứng dụng của lĩnh vực tối ưu có ràng buộc
Tập điều kiện Karush-Kuhn-Tucker


- [Eq.14] chính là tập các ràng buộc ban đầu
- Điều kiện bổ sung [Eq.16] chỉ ra rằng chỉ những ví dụ (điểm dữ liệu) thuộc các mặt siêu phẳng lề (H+ và H-) mới có a𝑖 > 0 – bởi vì với những ví đụ đó thì 𝑦𝑖(<w × x> + b) − 1 = 0 →Những ví dụ (điểm dữ liệu) này được gọi là các vectơ hỗ trợ!
- Đối với các ví dụ khác (không phải là các vectơ hỗ trợ) thì a𝑖 = 0
Học SVM: giải bài toán cực tiểu hóa
- Trong trường hợp tổng quát, các điều kiện Karush-Kuhn- Tucker là cần đối với một lời giải tối ưu, nhưng chưa đủ
- Tuy nhiên đối với SVM, bài toán cực tiểu hóa có hàm mục tiêu lồi (convex) và các ràng buộc tuyến tính, thì các điều kiện Karush-Kuhn-Tucker là cần và đủ đối với một lời giải tối ưu
- Giải quyết bài toán tối ưu này vẫn là một nhiệm vụ khó khăn, do sự tồn tại của các ràng buộc bất đẳng thức!
- Phương pháp Lagrange giải quyết bài toán tối ưu hàm lồi dẫn đến một bài toán đối ngẫu (dual) của bài toán tối ưu → Dễ giải quyết hơn so với bài toán tối ưu ban đầu (primal)
Học SVM: biểu thức đối ngẫu
- Để thu được biểu thức đối ngẫu từ biểu thức ban đầu:
→Gán giá trị bằng 0 đối với các đạo hàm bộ phận của biểu thức Lagrange trong [Eq.11] đối với các biến ban đầu (w và b)
→Sau đó, áp dụng các quan hệ thu được đối với biểu thức Lagrange
-
- Tức là: áp dụng các biểu thức [Eq.12-13] vào biểu thức Lagrange ban đầu ([Eq.11]) để loại bỏ các biến ban đầu (w và b)
- Biểu thức đối ngẫu LD

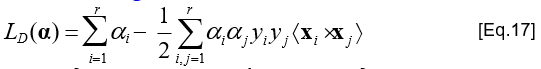
- Cả hai biểu thức LP và LD đều là các biểu thức Lagrange
- Dựa trên cùng một hàm một tiêu – nhưng với các ràng buộc khác nhau
- Lời giải tìm được, bằng cách cực tiểu hóa LP hoặc cực đại hóa LD
Bài toán tối ưu đối ngẫu

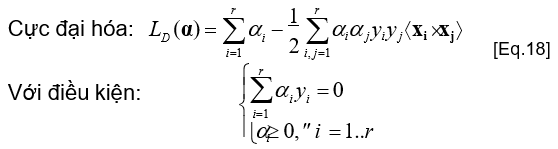
- Đối với hàm mục tiêu là hàm lồi và các ràng buộc tuyến tính, giá trị cực đại của LD xảy ra tại cùng các giá trị của w, b và ai giúp đạt được giá trị cực tiểu của LP
- Giải bài toán [Eq.18], ta thu được các hệ số nhân Lagrange ai (các hệ số ai này sẽ được dùng để tính w và b)
- Giải bài toán [Eq.18] cần đến các phương pháp lặp (để giải quyết bài toán tối ưu hàm lồi bậc hai có các ràng buộc tuyến tính)
→ Chi tiết các phương pháp này nằm ngoài phạm vi của bài giảng!
Tính các giá trị w* và b*
- Gọi SV là tập các vectơ hỗ trợ
- SV là tập con của tập 𝑟 các ví dụ huấn luyện ban đầu
→a𝑖 > 0 đối với các vectơ hỗ trợ 𝒙𝒊
→a𝑖 = 0 đối với các vectơ không phải là vectơ hỗ trợ 𝒙𝒊
- Sử dụng biểu thức [Eq.12], ta có thể tính được giá trị 𝒘∗
- Sử dụng biểu thức [Eq.16] và (bất kỳ) một vectơ hỗ trợ 𝒙𝑘, ta có
- a𝑘[𝑦𝑘( 𝒘∗, 𝒙𝑘 + 𝑏∗) − 1] = 0
- Nhớ rằng a𝑘 > 0 đối với mọi vectơ hỗ trợ 𝒙𝑘
- Vì vậy: 𝑦𝑘 𝒘∗, 𝒙𝑘 + 𝑏∗ − 1 = 0
- Từ đây, ta tính được giá trị 𝑏∗ = 𝑦: − (𝒘∗, 𝒙𝑘 )
Phân lớp cho ví dụ mới
- Ranh giới quyết định phân lớp được xác định bởi siêu phẳng:

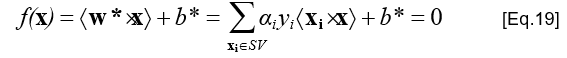
- Đối với một ví dụ cần phân lớp z, cần tính giá trị:

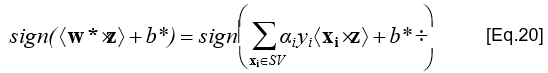
→ Nếu biểu thức [Eq.20] trả về giá trị 1, thì ví dụ z được phân vào lớp có nhãn dương (positive); ngược lại, được phân vào lớp có nhãn âm (negative)
- Việc phân lớp này:
- Chỉ phụ thuộc vào các vectơ hỗ trợ
- Chỉ cần giá trị tích vô hướng (tích trong) của 2 vectơ (chứ không cần biết giá trị của 2 vectơ đấy)
Linear SVM: Không phân tách được
- Phương pháp SVM trong trường hợp hai lớp không thể phân tách được bằng một siêu phẳng?
- Trường hợp phân lớp tuyến tính và phân tách được là lý tưởng (ít xảy ra)
- Tập dữ liệu có thể chứa nhiễu, lỗi (vd: một số ví dụ được gán nhãn lớp sai)
- Đối với trường hợp phân tách được, bài toán tối ưu:

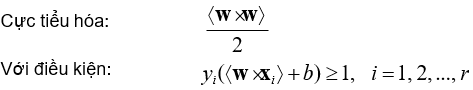
- Nếu tập dữ liệu chứa nhiễu, các điều kiện có thể không được thỏa mãn
→ Không tìm được lời giải (w* và b*)!
Hai ví dụ nhiễu xa và xb được gán nhãn lớp sai

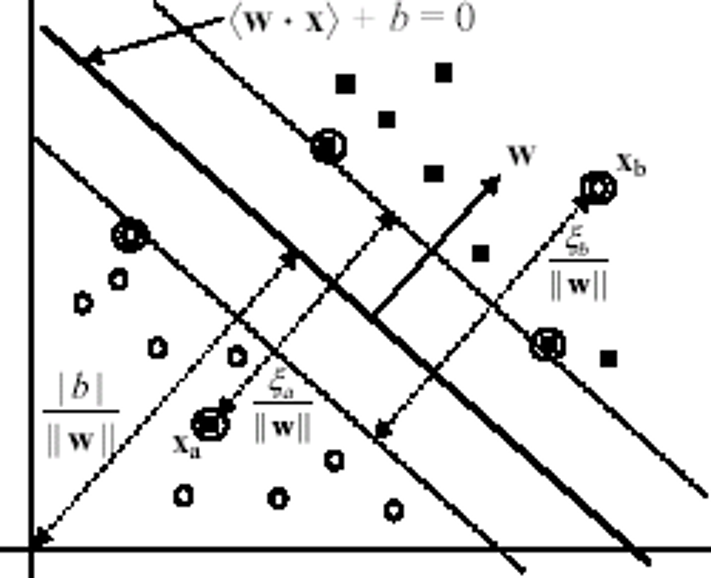
Nới lỏng điều kiện
- Để làm việc với các dữ liệu chứa nhiễu, cần nới lỏng các điều kiện lề (margin constraints) bằng cách sử dụng các biến slack xi (³ 0)


- Đối với một ví dụ nhiễu/lỗi: xi >1
- Các điều kiện mới đối với trường hợp (phân lớp tuyến tính) không thể phân tách được:

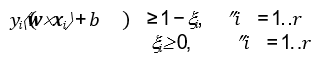
Tích hợp lỗi trong hàm mục tiêu
- Cần phải tích hợp lỗi trong hàm tối ưu mục tiêu
- Bằng cách gán giá trị chi phí (cost) cho các lỗi, và tích hợp chi phí này trong hàm mục tiêu mới:
Cực tiểu hóa:

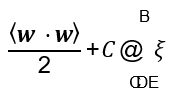
trong đó C (>0) là tham số xác định mức độ phạt (penalty degree) đối với các lỗi
→ Giá trị C càng lớn, thì mức độ phạt càng cao đối với các lỗi
Bài toán tối ưu mới

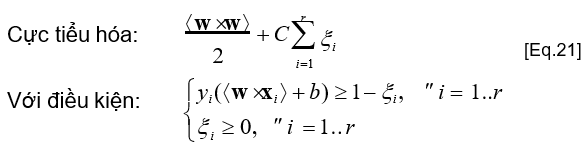
- Bài toán tối ưu mới này được gọi là Soft-margin SVM
- Giải bài toán này tương đương với việc cực tiểu hoá hàm

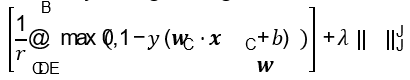
- Trong đó
- max 0, 1 − 𝑦C(𝒘 ⋅ 𝒙C + 𝑏) thường được gọi là Hinge loss
- 𝜆 là tham số
- Biểu thức tối ưu Lagrange:

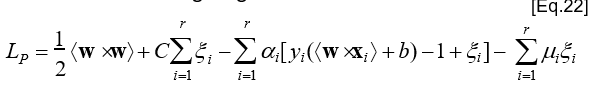
trong đó ai (³0) và mi (³0) là các hệ số nhân Lagrange
Tập điều kiện Karush-Kuhn-Tucker

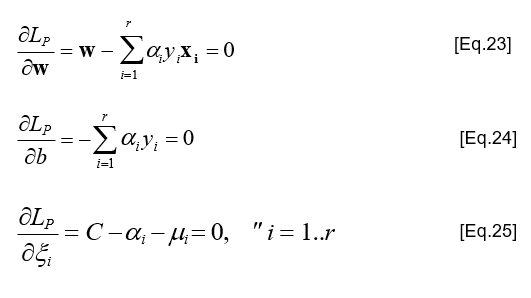
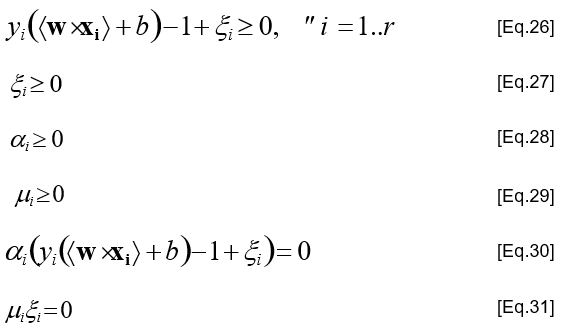

Chuyển về biểu thức đối ngẫu
- Giống như với trường hợp dữ liệu có thể phân tách được, chúng ta chuyển biểu thức Lagrange từ dạng ban đầu (primal formulation) về dạng đối ngẫu (dual formulation)
- Gán giá trị bằng 0 cho các đạo hàm bộ phận của biểu thức Lagrange ([Eq.22]) đối với các biến ban đầu (w, b, xi)
- Thay thế các kết quả thu được vào biểu thức Lagrange ban đầu
→ Sử dụng các kết quả của các biểu thức [Eq.23-25] để thay thế vào trong biểu thức Lagrange ban đầu [Eq.22]
- Từ biểu thức [Eq.25], ta có: C - ai - mi = 0,
- và bởi vì: mi ³0,
- nên ta suy ra điều kiện: ai £C
Biểu thức đối ngẫu

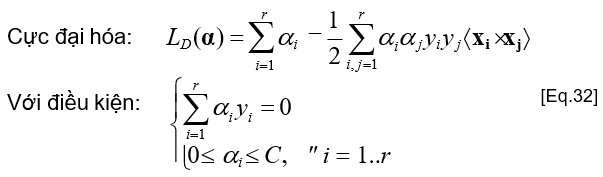
- xi và các hệ số nhân Lagrange của chúng (mi) không xuất hiện trong biểu thức đối ngẫu
→ Hàm mục tiêu giống hệt như đối với bài toán phân lớp tuyến tính phân tách được (separable linear classification)!
- Khác biệt duy nhất là tập các ràng buộc mới: ai £C
Tìm lời giải cho các biến ban đầu
- Bài toán đối ngẫu [Eq.32] được giải quyết bằng các phương pháp lặp (để giải quyết bài toán tối ưu hàm lồi bậc hai có các ràng buộc tuyến tính)
- Các giá trị (hệ số nhân Lagrange) ai lời giải được sử dụng để tính toán w* và b*
- w* được xác định sử dụng biểu thức [Eq.23]
- b* được xác định sử dụng các điều kiện bổ sung Karush-Kuhn- Tucker trong [Eq.30-31] …nhưng, có vấn đề: xi chưa biết!
- Để tính được b*
- Từ [Eq.25] và [Eq.31], ta suy ra được: xi=0 nếu ai<C
- Vì vậy, ta có thể sử dụng một ví dụ học xk thỏa mãn điều kiện (0<ak<C) và [Eq.30] (với xk =0) để tính toán b*
- Đến đây, việc tính toán b* tương tự như với trường hợp phân lớp tuyến tính phân tách được!
Các đặc điểm quan trọng
- Từ các biểu thức [Eq.25-31], ta có thể suy ra các kết luận sau:
If ai = 0 then 𝑦𝑖(<w × x> + b) ≥ 1, and xi = 0
If 0 < ai < C then 𝑦𝑖(<w × x> + b) = 1, and xi = 0
If ai = C then 𝑦𝑖(<w × x> + b) < 1, and xi > 0
- Biểu thức [Eq.33] thể hiện một đặc điểm rất quan trọng của SVM
- Lời giải được xác định dựa trên rất ít (sparse) các giá trị ai
- Rất nhiều ví dụ học nằm ngoài khoảng lề (margin area), và chúng có giá trị a𝑖 bằng 0
- Các ví dụ nằm trên lề (𝑦𝑖(á𝒘´𝒙𝑖ñ + 𝑏) = 1 – chính là các vectơ hỗ trợ), thì có giá trị a𝑖 khác không (0 < a𝑖 < 𝐶)
- Các ví dụ nằm trong khoảng lề (yi(áw´xiñ+b)<1 – là các ví dụ nhiễu/lỗi), thì có giá trị a𝑖 = 𝐶
- Nếu không có đặc điểm thưa thớt (sparsity) này, thì phương pháp SVM không thể hiệu quả đối với các tập dữ liệu lớn
- Lời giải được xác định dựa trên rất ít (sparse) các giá trị ai
Ranh giới quyết định phân lớp
- Ranh giới quyết định phân lớp chính là siêu phẳng:
→ Rất nhiều ví dụ học xi có giá trị ai bằng 0! (chính là đặc điểm thưa thớt – sparsity – của phương pháp SVM)
- Đối với một ví dụ cần phân loại z, nó được phân loại bởi:
𝑠𝑖𝑔𝑛( 𝒘∗, 𝒛 + 𝑏∗)
- Cần xác định giá trị phù hợp của tham số C (trong hàm tối ưu mục tiêu)
→ Thường được xác định bằng cách sử dụng một tập dữ liệu tối ưu (validation set)
Linear SVM: Tổng kết
- Sự phân lớp dựa vào siêu phẳng phân tách
- Siêu phẳng phân tách được xác định dựa trên tập các vectơ hỗ trợ
- Chỉ đối với các vectơ hỗ trợ, thì hệ số nhân Lagrange của chúng khác 0
- Đối với các ví dụ huấn luyện khác (không phải là các vectơ hỗ trợ), thì hệ số nhân Lagrange của chúng bằng 0
- Việc xác định các vectơ hỗ trợ (trong số các ví dụ huấn luyện) đòi hỏi phải giải quyết bài toán tối ưu bậc hai
- Trong biểu thức đối ngẫu (LD) và trong biểu thức biểu diễn siêu phẳng phân tách, các ví dụ huấn luyện chỉ xuất hiện bên trong các tích vô hướng (inner/dot-products) của các vectơ
Non-linear SVM
- Lưu ý: Các công thức trong phương pháp SVM đòi hỏi tập dữ liệu phải có thể phân lớp tuyến tính (có/không nhiễu)
- Trong nhiều bài toán thực tế, thì các tập dữ liệu có thể là phân lớp phi tuyến (non-linearly separable)
- Phương pháp phân loại SVM phi tuyến (Non-linear SVM):
- Bước 1. Chuyển đổi không gian biểu diễn đầu vào ban đầu sang một không gian khác (thường có số chiều lớn hơn nhiều)
- → Dữ liệu được biểu diễn trong không gian mới (đã chuyển đổi) có thể phân lớp tuyến tính (linearly separable)
- Bước 2. Áp dụng lại các công thức và các bước như trong phương pháp phân lớp SVM tuyến tính
- Không gian biểu diễn ban đầu: Không gian đầu vào (input space)
- Không gian biểu diễn sau khi chuyển đổi: Không gian đặc trưng (feature space)
Chuyển đổi không gian biểu diễn
- Ý tưởng cơ bản là việc ánh xạ (chuyển đổi) biểu diễn dữ liệu từ không gian ban đầu X sang một không gian khác F bằng cách áp dụng một hàm ánh xạ phi tuyến f
f : X ® F
x ! f(x)
- Trong không gian đã chuyển đổi, tập các ví dụ học ban đầu {(𝒙𝟏, 𝑦1), (𝒙𝟐, 𝑦2), … , (𝒙𝒓, 𝑦𝑟)} được biểu diễn (ánh xạ) tương ứng:
{(f(x1), y1), (f(x2), y2), …, (f(xr), yr)}

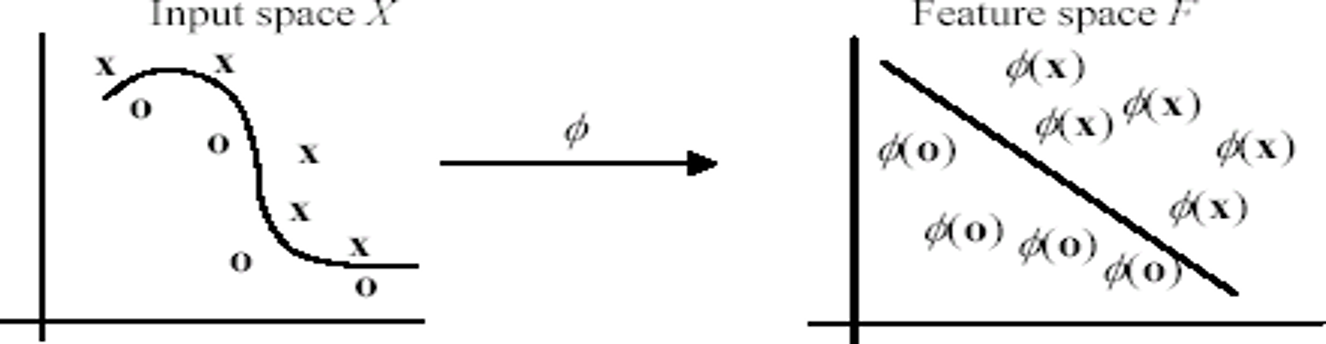
- Trong ví dụ này, không gian sau chuyển đổi vẫn là có số chiều bằng không gian ban đầu (2 chiều)
- Nhưng thông thường, số chiều của không gian sau chuyển đổi (feature space) lớn hơn (nhiều) số chiều của không gian ban đầu (input space)
Non-linear SVM: Bài toán tối ưu


Chuyển đổi không gian: Ví dụ
- Xét không gian biểu diễn ban đầu có 2 chiều, và chúng ta chọn hàm ánh xạ từ không gian ban đầu (2-D) sang không gian mới (3-D) như sau:
𝑥E, 𝑥J ↦ (𝑥E, 𝑥J, 2𝑥E𝑥J)
- Xét ví dụ học (𝒙 = (2, 3), 𝑦 = −1) trong không gian ban đầu (2-D)
- Trong không gian sau chuyển đổi (3-D), thì ví dụ học này được biểu diễn như sau:
(f(𝒙) = (4, 9, 8.49), 𝑦 = −1)
Chuyển đổi không gian: Trở ngại
- Việc chuyển đổi không gian một cách trực tiếp có thể gặp vấn đề về số chiều không gian quá lớn (curse of dimensionality)
- Ngay cả với một không gian ban đầu có số chiều không lớn, một hàm chuyển đổi (ánh xạ) thích hợp có thể trả về một không gian mới có số chiều rất lớn
→ “thích hợp” ở đây mang ý nghĩa là hàm chuyển đổi cho phép xác định không gian mới mà trong đó tập dữ liệu có thể phân lớp tuyến tính
- Vấn đề: Chi phí tính toán quá lớn đối với việc chuyển đổi không gian trực tiếp
- Rất may, việc chuyển đổi không gian trực tiếp là không cần thiết…
Các hàm nhân (Kernel functions)
- Trong biểu thức đối ngẫu ([Eq.35]) và trong biểu thức siêu phẳng phân tách ([Eq.36]):
- Việc xác định trực tiếp (cụ thể) giá trị f(x) và f(z) là không cần thiết
- Chỉ cần tính giá trị tích vô hướng vectơ áf(x)´f(z)ñ
→ Việc chuyển đổi không gian trực tiếp là không cần thiết!
- Nếu có thể tính được tích vô hướng vectơ áf(x)´f(z)ñ trực tiếp từ các vectơ x và z, thì không cần phải xác định (không cần biết):
- vectơ đặc trưng (trong không gian sau chuyển đổi) f(x), và
- hàm chuyển đổi (ánh xạ) f
- Trong phương pháp SVM, mục tiêu này đạt được thông qua việc sử dụng các hàm nhân (kernel functions), được ký hiệu là K
Kernel trick
- Diễn giải chi tiết của các bước tính toán trong ví dụ trên chỉ mang mục đích giải thích (minh họa)
- Trong thực tế, ta không cần phải tìm (xác định) hàm ánh xạ f
- Bởi vì: Ta có thể áp dụng hàm nhân một cách trực tiếp
→Thay thế tất cả các giá trị tích vô hướng vectơ
f(x) và f(z) trong [Eq.35-36] bằng một hàm nhân được
chọn K(x,z) (ví dụ: hàm nhân đa thức áx´zñd trong [Eq.38])
- Chiến lược này được gọi là kernel trick!
Phân lớp bằng SVM: Các vấn đề
- SVM chỉ làm việc với không gian đầu vào là các số thực
→ Đối với các thuộc tính định danh (nominal), cần chuyển các giá trị định danh thành các giá trị số
- SVM chỉ làm việc (thực hiện phân lớp) với 2 lớp
→ Đối với các bài toán phân lớp gồm nhiều lớp, cần chuyển thành một tập các bài toán phân lớp gồm 2 lớp, và sau đó giải quyết riêng rẽ từng bài toán 2 lớp này
→ Ví dụ: chiến lược “one-against-rest”
- Siêu phẳng phân tách (ranh giới quyết định phân lớp) xác định được bởi SVM thường khó hiểu đối với người dùng
- Vấn đề (khó giải thích quyết định phân lớp) này càng nghiêm trọng, nếu các hàm nhân (kernel functions) được sử dụng
- SVM thường được dùng trong các bài toán ứng dụng mà trong đó việc giải thích hoạt động (quyết định) của hệ thống cho người dùng không phải là một yêu cầu quan trọng
Bài viết nổi bật





Bài viết nổi bật