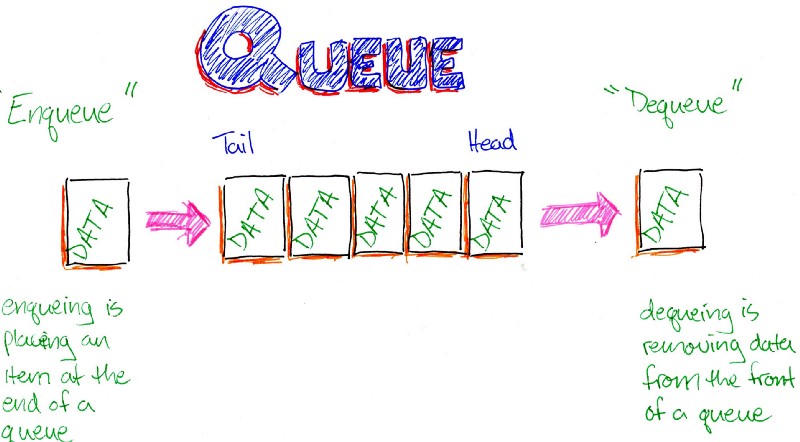
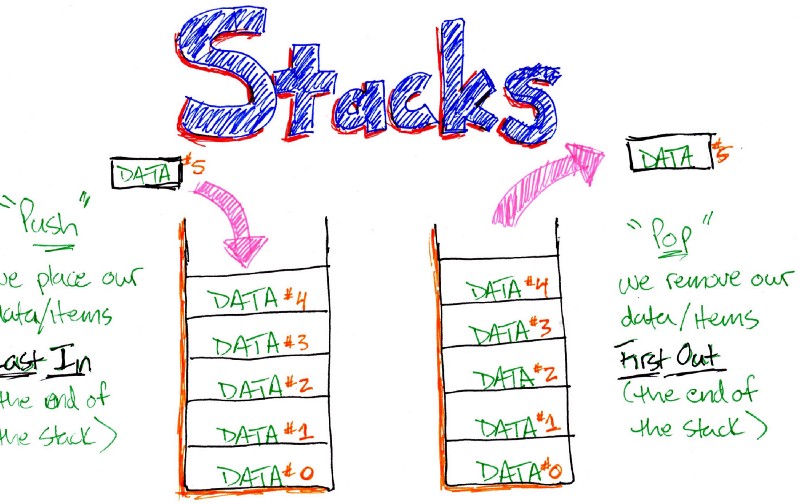
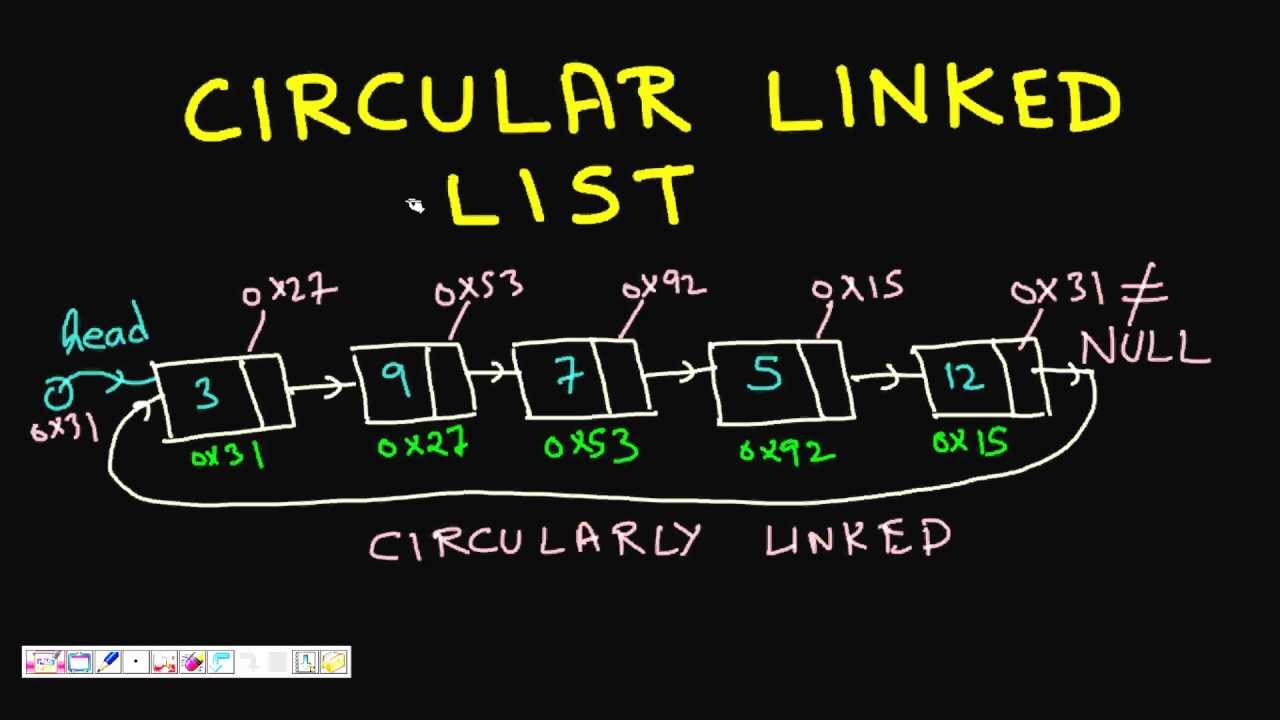
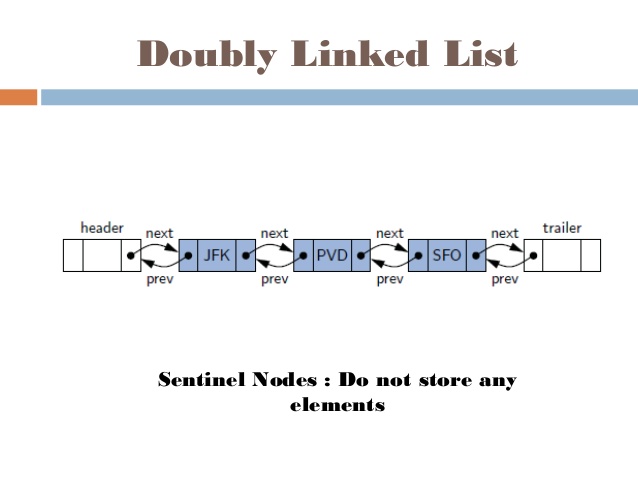
Bài 39 - Dãy Fibonacci trong cấu trúc dữ liệu & giải thuật
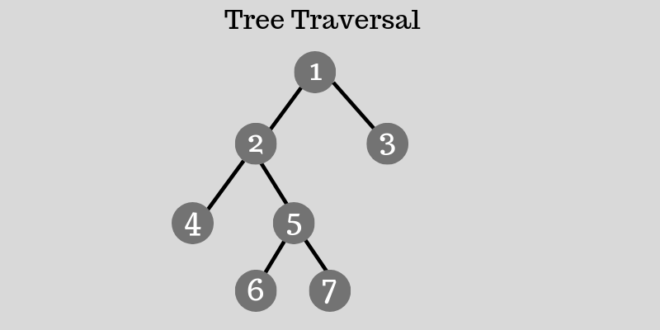
Dãy Fibonacci tạo dãy các số bằng cách cộng hai số đằng trước. Dãy Fibonacci bắt đầu từ hai số: F0 & F1. Giá trị ban đầu của F0 & F1 có thể tương ứng là 0, 1 hoặc 1, 1.