Trong chương này, chúng tôi sẽ liệt kê các phương pháp, phương pháp và kỹ thuật React hay nhất sẽ giúp chúng tôi luôn nhất quán trong quá trình phát triển ứng dụng.
Các component bậc cao hơn là các hàm JavaScript được sử dụng để thêm các chức năng bổ sung vào component hiện có. Các hàm này thuần túy , có nghĩa là chúng đang nhận dữ liệu và trả về các giá trị theo dữ liệu đó.
Trong chương này, chúng ta sẽ học cách triển khai mẫu dòng trong các ứng dụng React. Chúng tôi sẽ sử dụng khung Redux . Mục tiêu của chương này là trình bày ví dụ đơn giản nhất về mọi phần cần thiết để kết nối Redux và React .
Flux là một khái niệm lập trình, trong đó dữ liệu là một hướng . Dữ liệu này đi vào ứng dụng và chảy qua ứng dụng theo một hướng cho đến khi hiển thị trên màn hình.
Các Keys React hữu ích khi làm việc với các component được tạo động hoặc khi danh sách của bạn bị người dùng thay đổi. Đặt giá trị khóa sẽ giữ cho các component của bạn được nhận dạng duy nhất sau khi thay đổi.
Các ref được sử dụng để trả về một tham chiếu đến phần tử. Refs nên tránh trong hầu hết các trường hợp, tuy nhiên, chúng có thể hữu ích khi chúng ta cần các phép đo DOM hoặc để thêm các phương thức vào các component.
Trong chương này, chúng tôi sẽ giải thích component API React. Chúng ta sẽ thảo luận về ba phương thức: setState (), forceUpdate và ReactDOM.findDOMNode ()
Xác nhận thuộc tính là một cách hữu ích để buộc sử dụng đúng các component. Điều này sẽ giúp trong quá trình phát triển để tránh các lỗi và sự cố trong tương lai, khi ứng dụng trở nên lớn hơn. Nó cũng làm cho code dễ đọc hơn, vì chúng ta có thể thấy cách sử dụng từng component.
Sự khác biệt chính giữa state và props là props không biến đổi. Đây là lý do tại sao các component cha phải xác định trạng thái có thể cập nhật và thay đổi, trong khi các component con chỉ nên truyền dữ liệu từ trạng thái bằng cách sử dụng props
State là nơi bắt nguồn của dữ liệu. Chúng ta nên luôn cố gắng làm cho trạng thái của mình đơn giản nhất có thể và giảm thiểu số lượng các thành phần trạng thái. Ví dụ: nếu chúng ta có mười thành phần cần dữ liệu từ trạng thái, chúng ta nên tạo một thành phần chứa sẽ giữ trạng thái cho tất cả chúng.
Trong chương này, chúng ta sẽ học cách kết hợp các component để làm cho ứng dụng dễ bảo trì hơn. Cách tiếp cận này cho phép cập nhật và thay đổi các component của bạn mà không ảnh hưởng đến phần còn lại của trang.
ReactJS là thư viện JavaScript được sử dụng để xây dựng các thành phần UI có thể tái sử dụng. React được sử dụng tại Facebook trong production, và instagram được viết hoàn toàn trên React
React là một thư viện front-end do Facebook phát triển. Nó được sử dụng để xử lý lớp (view layer) cho các ứng dụng web và thiết bị di động. ReactJS cho phép chúng ta tạo các thành phần UI có thể tái sử dụng. Nó hiện là một trong những thư viện JavaScript phổ biến nhất và có nền tảng vững chắc cũng như cộng đồng lớn đằng sau nó.
Python là một ngôn ngữ lập trình bậc cao, thông dịch, hướng đối tượng, đa mục đích và cũng là một ngôn ngữ lập trình động. Nó được tạo ra bởi Guido van Rossum trong giai đoạn 1985-1990. Giống như Perl, mã nguồn Python hiện có sẵn theo giấy phép GNU (GPL).
Neural Networks là một giải thuật của học máy…
Còn được gọi là mạng thần kinh nhân tạo, là một thể loại giải thuật của học máy — machine learning, lấy cảm hứng từ bộ não con người.
Máy vectơ hỗ trợ (Support vector machine - SVM) được đề cử bởi V. Vapnik và các đồng nghiệp của ông vào những năm 1970s ở Nga, và sau đó đã trở nên nổi tiếng và phổ biến vào những năm 1990s
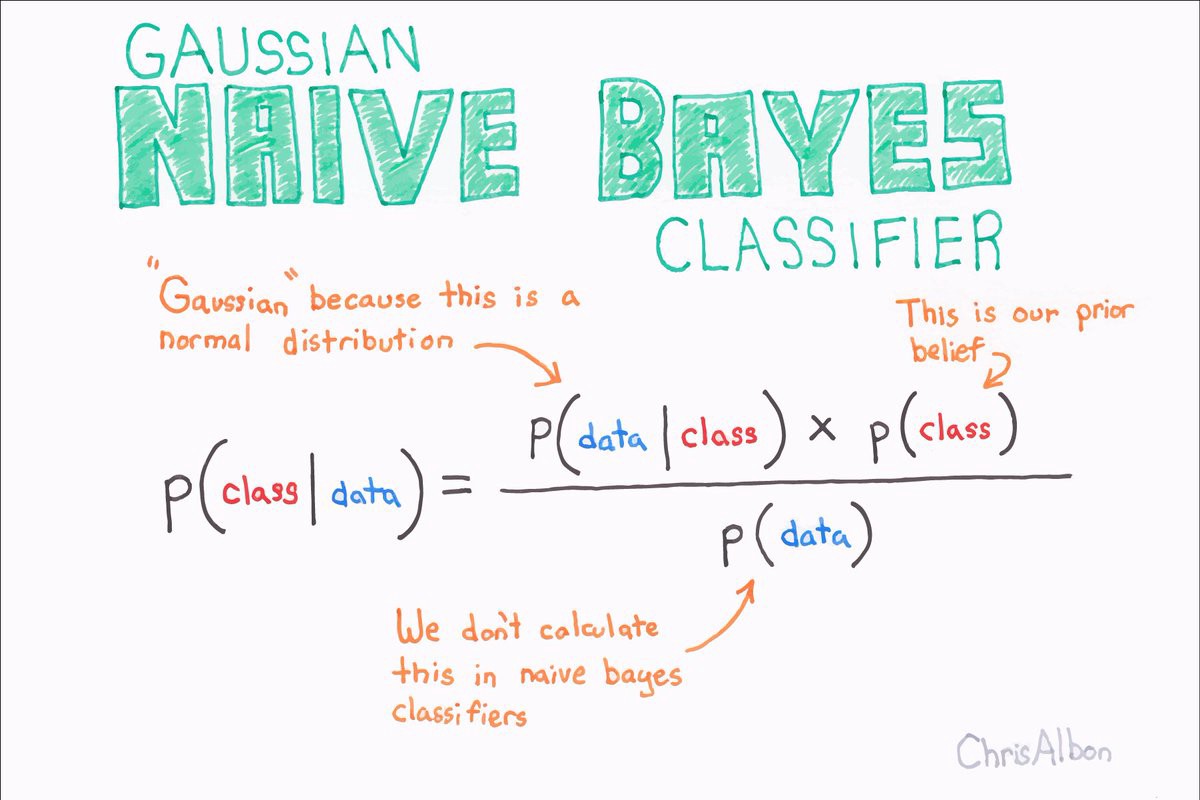
Definition (Machine learning (ML))
Tom Mitchell - "Máy tính được gọi là học từ kinh nghiệm (dữ liệu) E với tác vụ (dự đoán, phân lớp, gom nhóm) T và được đánh giá bởi độ đo (độ chính xác) P nêu máy tính khiển tác vụ T này cải thiện được độ chính xác P thông qua dữ liệu E cho trước. "
Các kỹ thuật tìm kiếm mù rất kém hiệu quả, trong nhiều trường hợp không sử dụng được.
Trong chương này, nghiên cứu:
Các phương pháp tìm kiếm kinh nghiệm (tìm kiếm heuristic).
Các phương pháp sử dụng hàm đánh giá.
Dãy Fibonacci tạo dãy các số bằng cách cộng hai số đằng trước. Dãy Fibonacci bắt đầu từ hai số: F0 & F1. Giá trị ban đầu của F0 & F1 có thể tương ứng là 0, 1 hoặc 1, 1.
Một số ngôn ngữ lập trình cho phép việc một module hoặc một hàm được gọi tới chính nó. Kỹ thuật này được gọi là Đệ qui (Recursion). Trong đệ qui, một hàm a có thể: gọi trực tiếp chính hàm a này hoặc gọi một hàm b mà trả về lời gọi tới hàm a ban đầu. Hàm a được gọi là hàm đệ qui.
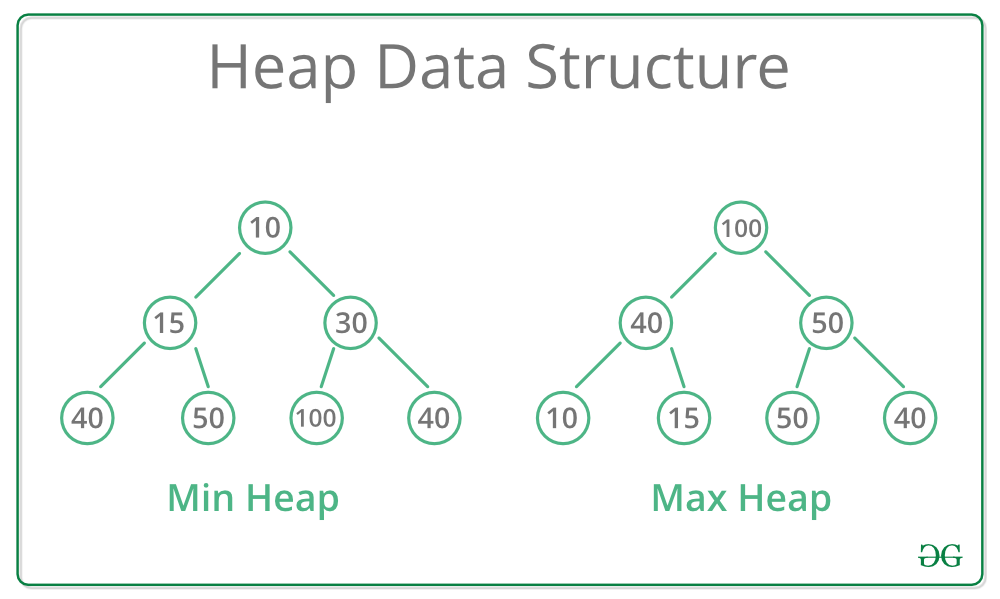
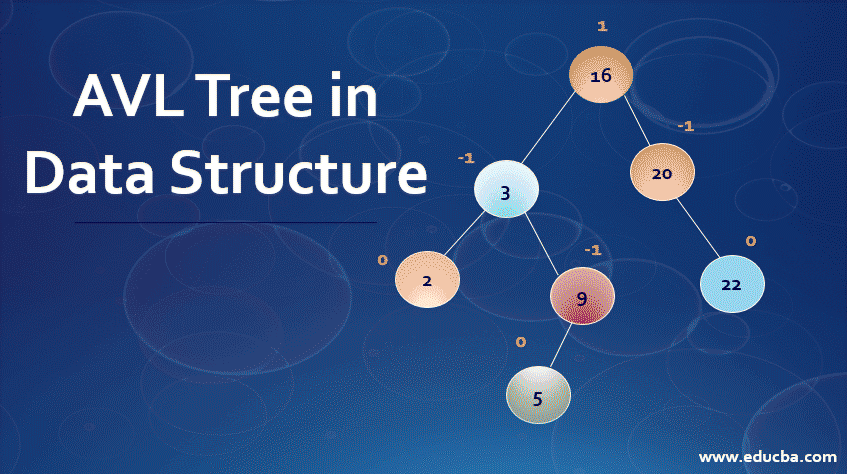
Cấu trúc dữ liệu Heap là một trường hợp đặc biệt của cấu trúc dữ liệu cây nhị phân cân bằng, trong đó khóa của nút gốc được so sánh với các con của nó và được sắp xếp một cách phù hợp
Một cây khung là một tập con của Grahp G mà có tất cả các đỉnh được bao bởi số cạnh tối thiểu nhất. Vì thế, một cây khung sẽ không hình thành một vòng tuần hoàn và nó cũng không thể bị ngắt giữa chừng.
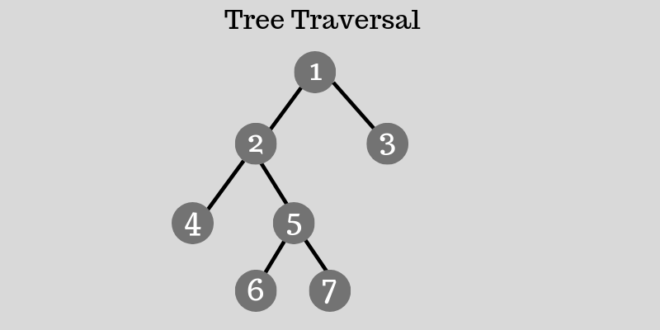
Duyệt cây là một tiến trình để truy cập tất cả các nút của một cây và cũng có thể in các giá trị của các nút này. Bởi vì tất cả các nút được kết nối thông qua các cạnh (hoặc các link), nên chúng ta luôn luôn bắt đầu truy cập từ nút gốc.
Giải thuật tìm kiếm theo chiều rộng (Breadth First Search – viết tắt là BFS) duyệt qua một đồ thị theo chiều rộng và sử dụng hàng đợi (queue) để ghi nhớ đỉnh liền kề để bắt đầu việc tìm kiếm khi không gặp được đỉnh liền kề trong bất kỳ vòng lặp nào.
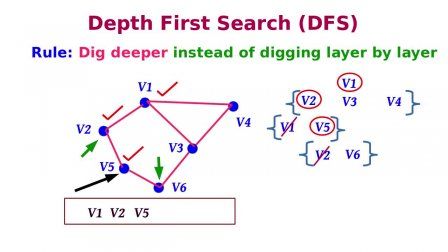
Giải thuật tìm kiếm theo chiều sâu (Depth First Search – viết tắt là DFS), còn được gọi là giải thuật tìm kiếm ưu tiên chiều sâu, là giải thuật duyệt hoặc tìm kiếm trên một cây hoặc một đồ thị và sử dụng stack (ngăn xếp) để ghi nhớ đỉnh liền kề để bắt đầu việc tìm kiếm khi không gặp được đỉnh liền kề trong bất kỳ vòng lặp nào.
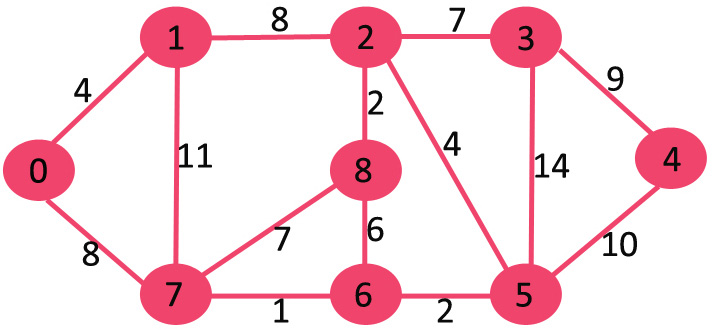
Một đồ thị (Graph) là một dạng biểu diễn hình ảnh của một tập các đối tượng, trong đó các cặp đối tượng được kết nối bởi các link. Các đối tượng được nối liền nhau được biểu diễn bởi các điểm được gọi là các đỉnh (vertices), và các link mà kết nối các đỉnh với nhau được gọi là các cạnh (edges).
Shell sort là một thuật toán sắp xếp hiệu quả cao và dựa trên thuật toán sắp xếp chèn. Thuật toán này tránh các dịch chuyển lớn như trong trường hợp sắp xếp chèn, nếu giá trị nhỏ hơn nằm ở bên phải và phải được chuyển sang bên trái.
Sắp xếp trộn (Merge Sort) là một giải thuật sắp xếp dựa trên giải thuật Chia để trị (Divide and Conquer). Với độ phức tạp thời gian trường hợp xấu nhất là Ο(n log n) thì đây là một trong các giải thuật đáng được quan tâm nhất.
Sắp xếp chọn là một thuật toán sắp xếp đơn giản. Thuật toán sắp xếp này là một thuật toán dựa trên so sánh tại chỗ, trong đó danh sách được chia thành hai phần, phần được sắp xếp ở đầu bên trái và phần chưa được sắp xếp ở đầu bên phải. Ban đầu, phần được sắp xếp trống và phần chưa sắp xếp là toàn bộ danh sách.
Sắp xếp chèn là một giải thuật sắp xếp dựa trên so sánh in-place. Ở đây, một danh sách con luôn luôn được duy trì dưới dạng đã qua sắp xếp. Sắp xếp chèn là chèn thêm một phần tử vào danh sách con đã qua sắp xếp. Phần tử được chèn vào vị trí thích hợp sao cho vẫn đảm bảo rằng danh sách con đó vẫn sắp theo thứ tự.
Sắp xếp nổi bọt là một thuật toán sắp xếp đơn giản. Thuật toán sắp xếp này là thuật toán dựa trên so sánh, trong đó mỗi cặp yếu tố liền kề được so sánh và các yếu tố được hoán đổi nếu chúng không theo thứ tự.
Sắp xếp là sắp xếp dữ liệu theo một định dạng cụ thể như theo thứ tự anphabet tăng/giảm dần, theo thứ tự số tăng/giảm dần. Trong khoa học máy tính, giải thuật sắp xếp xác định cách để sắp xếp dữ liệu theo một thứ tự nào đó.
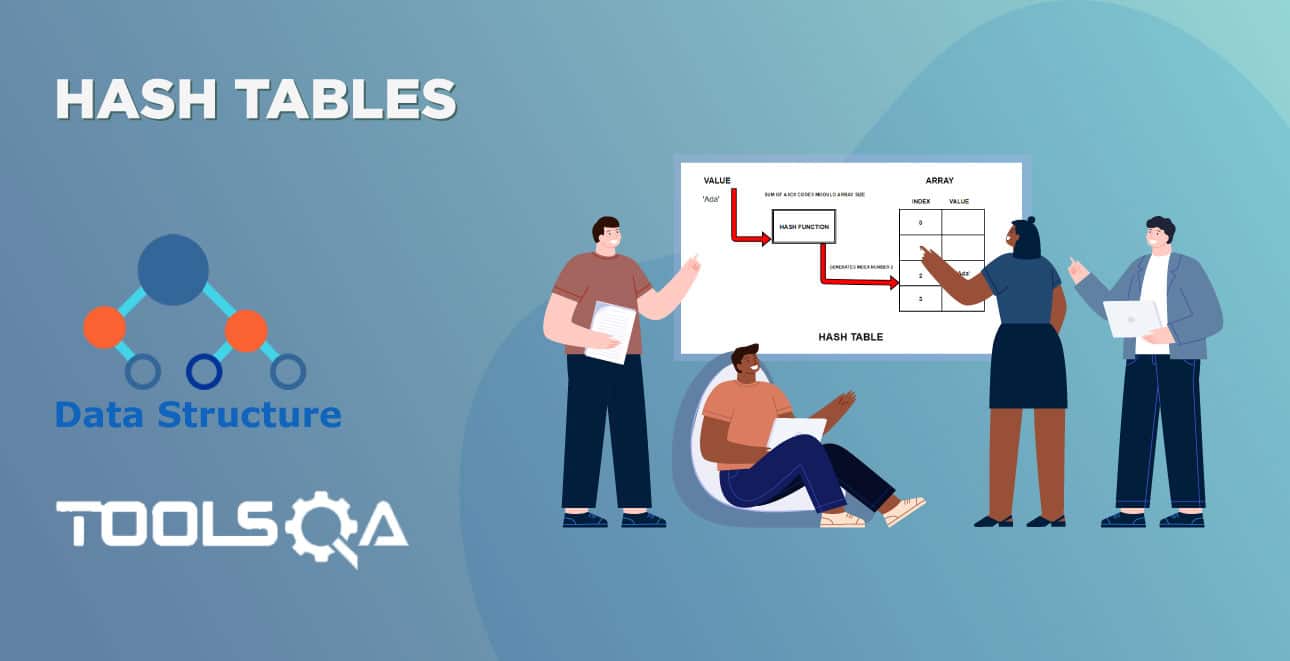
Cấu trúc dữ liệu Hash Table là một cấu trúc dữ liệu lưu giữ dữ liệu theo cách thức liên hợp. Trong Hash Table, dữ liệu được lưu giữ trong định dạng mảng, trong đó các giá trị dữ liệu có giá trị chỉ mục riêng. Việc truy cập dữ liệu trở nên nhanh hơn nếu chúng ta biết chỉ mục của dữ liệu cần tìm.
Tìm kiếm nội suy (Interpolation Search) là biến thể cải tiến của tìm kiếm nhị phân (Binary Search). Để giải thuật tìm kiếm này làm việc chính xác thì tập dữ liệu phải được sắp xếp.
Tìm kiếm nhị phân (Binary Search) là một giải thuật tìm kiếm nhanh với độ phức tạp thời gian chạy là Ο(log n). Giải thuật tìm kiếm nhị phân làm việc dựa trên nguyên tắc chia để trị (Divide and Conquer).
Tìm kiếm tuyến tính (Linear Search) là một giải thuật tìm kiếm rất cơ bản. Trong kiểu tìm kiếm này, một hoạt động tìm kiếm liên tiếp được diễn ra qua tất cả từng phần tử.
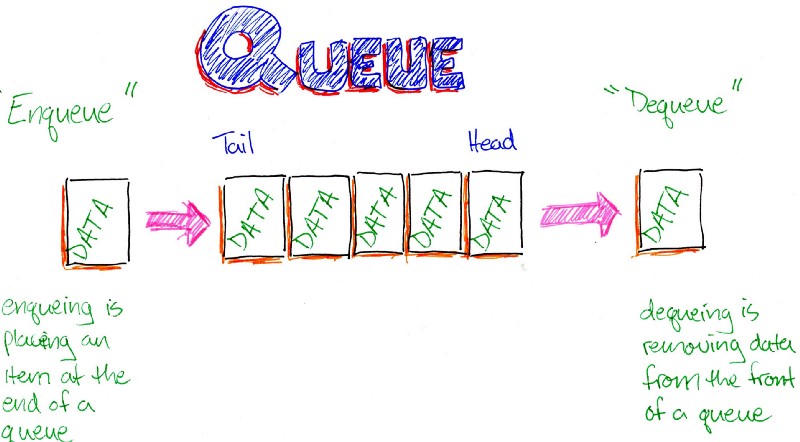
Hàng đợi (Queue) là một cấu trúc dữ liệu trừu tượng. Không giống như ngăn xếp, một hàng đợi được mở ở cả hai đầu của nó. Một đầu luôn được sử dụng để chèn dữ liệu (enqueue) và đầu kia được sử dụng để xóa dữ liệu (dequeue).
Cách viết biểu thức số học được gọi là ký hiệu . Một biểu thức số học có thể được viết bằng ba ký hiệu khác nhau nhưng tương đương, nghĩa là không thay đổi bản chất hoặc đầu ra của một biểu thức.
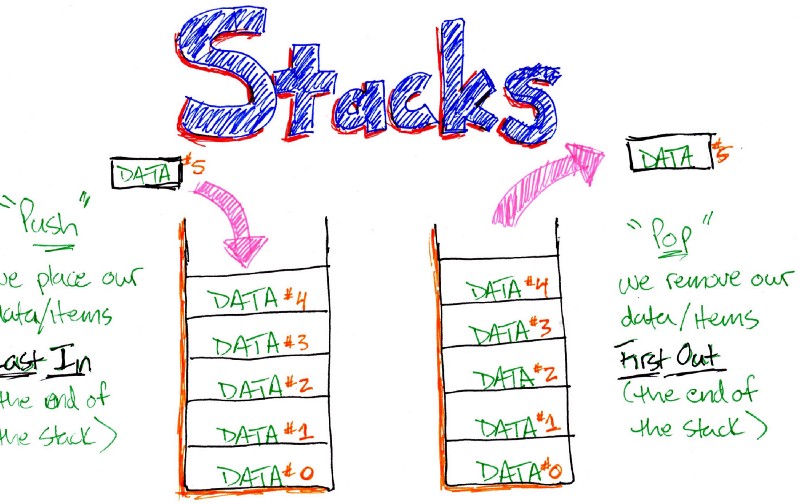
Ngăn xếp là cấu trúc dữ liệu trừu tượng (ADT), thường được sử dụng trong hầu hết các ngôn ngữ lập trình. Nó được đặt tên là stack vì nó hoạt động giống như một ngăn xếp trong thế giới thực
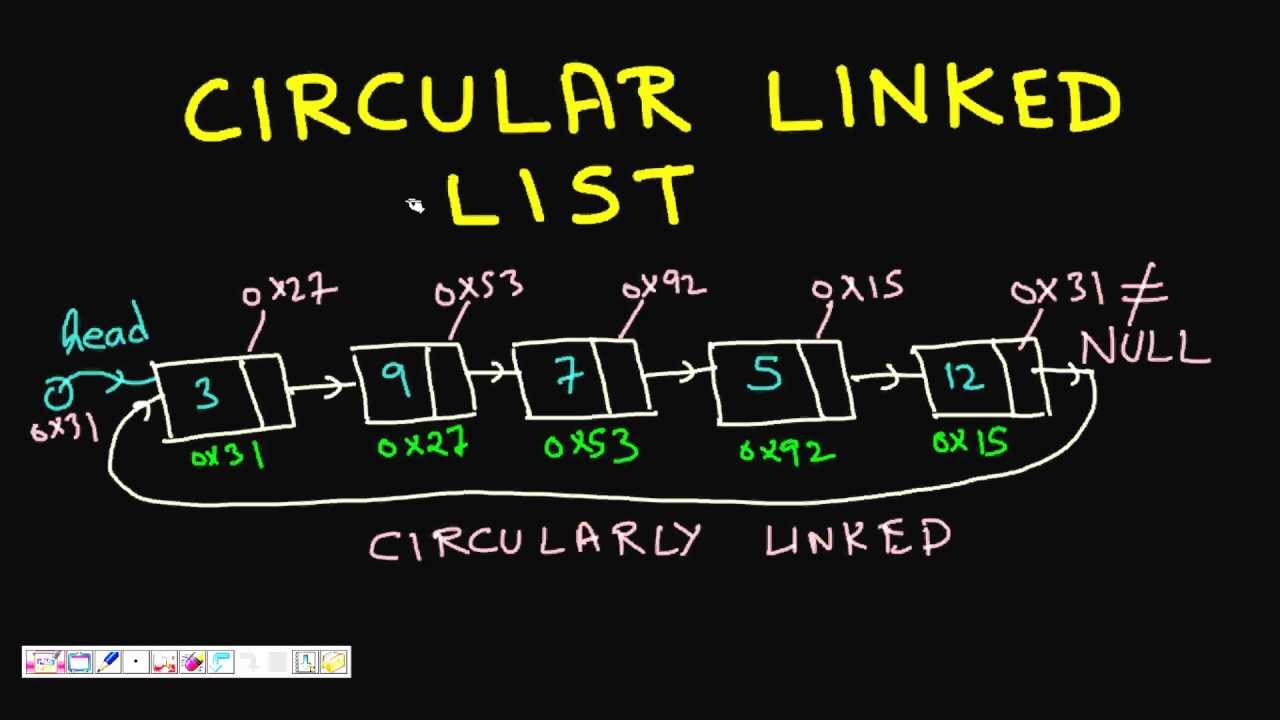
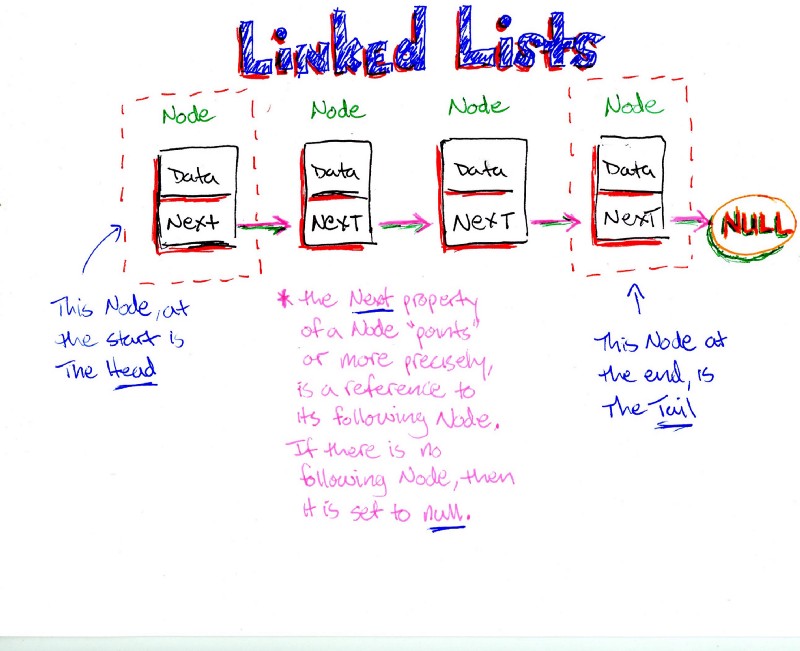
Danh sách liên kết vòng là một biến thể của danh sách được liên kết trong đó phần tử đầu tiên trỏ đến phần tử cuối cùng và phần tử cuối cùng trỏ đến phần tử đầu tiên. Cả Danh sách liên kết đơn và Danh sách liên kết đôi có thể được tạo thành một danh sách liên kết vòng.
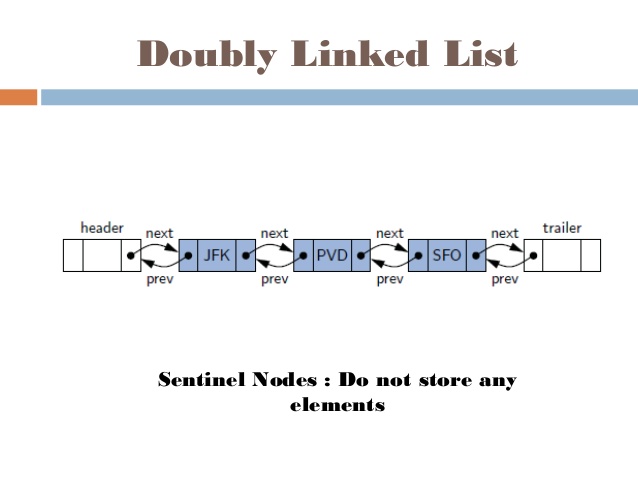
Danh sách liên kết đôi (Doubly Linked List) là một biến thể của danh sách liên kết (Linked List), trong đó hoạt động duyệt qua các nút có thể được thực hiện theo hai chiều: về trước và về sau một cách dễ dàng khi so sánh với Danh sách liên kết đơn.
Mảng (Array) là một trong các cấu trúc dữ liệu quan trọng nhất. Nó có thể lưu trữ một số phần tử cố định và các phần tử này nên có cùng kiểu. Hầu hết các cấu trúc dữ liệu sử dụng các mảng để thực hiện các thuật toán của chúng
Giải thuật Quy hoạch động (Dynamic Programming) giống như giải thuật chia để trị (Divide and Conquer) trong việc chia nhỏ bài toán thành các bài toán con nhỏ hơn và sau đó thành các bài toán con nhỏ hơn nữa có thể.
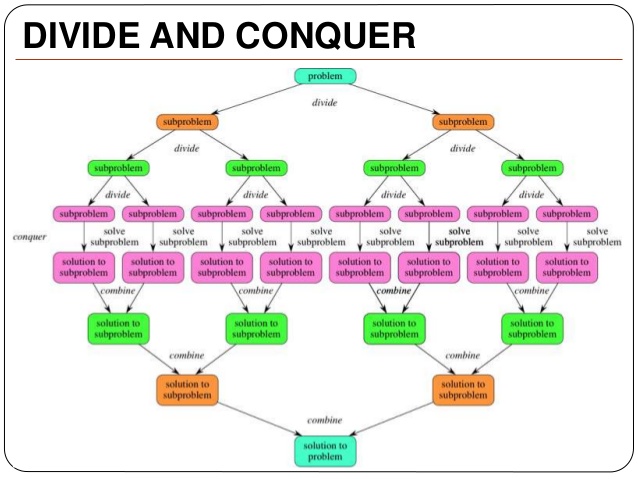
Giải thuật chia để trị (Divide and Conquer) là một phương pháp quan trọng trong việc thiết kế các giải thuật. Ý tưởng của phương pháp này khá đơn giản và rất dễ hiểu: Khi cần giải quyết một bài toán, ta sẽ tiến hành chia bài toán đó thành các bài toán con nhỏ hơn. Tiếp tục chia cho đến khi các bài toán nhỏ này không thể chia thêm nữa, khi đó ta sẽ giải quyết các bài toán nhỏ nhất này và cuối cùng kết hợp giải pháp của tất cả các bài toán nhỏ để tìm ra giải pháp của bài toán ban đầu.
Một thuật toán được thiết kế để đạt được giải pháp tối ưu cho một vấn đề nhất định. Theo cách tiếp cận thuật toán tham lam, các quyết định được đưa ra từ miền giải pháp đã cho. Vì tham lam, giải pháp gần nhất có vẻ cung cấp giải pháp tối ưu được chọn. Các thuật toán tham lam cố gắng tìm một giải pháp tối ưu cục bộ, cuối cùng có thể dẫn đến các giải pháp tối ưu hóa toàn cầu. Tuy nhiên, nhìn chung các thuật toán tham lam không cung cấp các giải pháp tối ưu hóa toàn cầu.
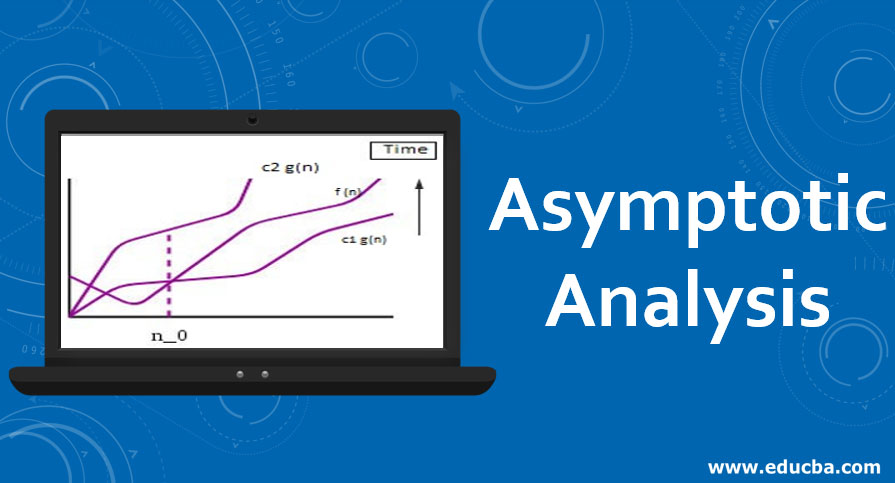
Phân tích tiệm cận của một thuật toán là khái niệm giúp chúng ta ước lượng được thời gian chạy của một thuật toán. Sử dụng phân tích tiệm cận, chúng tôi rất có thể kết luận trường hợp tốt nhất, trường hợp trung bình và trường hợp xấu nhất của một thuật toán.
Thuật toán là một quy trình từng bước, xác định một tập các hướng dẫn sẽ được thực hiện theo một thứ tự nhất định để có được đầu ra mong muốn. Các thuật toán thường được tạo ra độc lập với các ngôn ngữ cơ bản, tức là một thuật toán có thể được thực hiện bằng nhiều ngôn ngữ lập trình.
Cấu trúc dữ liệu là một cách có hệ thống để tổ chức dữ liệu để sử dụng nó một cách hiệu quả. Các thuật ngữ sau đây là các điều khoản nền tảng của một cấu trúc dữ liệu.
Cấu trúc dữ liệu là cách lưu trữ, tổ chức dữ liệu có thứ tự, có hệ thống để dữ liệu có thể được sử dụng một cách hiệu quả. Hầu hết mọi ứng dụng doanh nghiệp đều sử dụng các loại cấu trúc dữ liệu khác nhau theo một hoặc cách khác. Hướng dẫn này sẽ cung cấp cho bạn một sự hiểu biết lớn về cấu trúc dữ liệu cần thiết để hiểu được sự phức tạp của các ứng dụng cấp doanh nghiệp và nhu cầu của các thuật toán và cấu trúc dữ liệu.
Khái niệm về công nghệ AI xuất hiện đầu tiên bởi John McCarthy, một nhà khoa học máy tính Mỹ, vào năm 1956 tại Hội nghị The Dartmouth. Ngày nay, công nghệ AI là một thuật ngữ bao gồm tất cả mọi thứ từ quá trình tự động hoá robot đến người máy thực tế.
Một cuốn sách - KINH ĐIỂN - phải đọc của tất cả các lập trình viên Java
[Thinking in Java] đã được đánh giá rất cao bởi các lập trình viên trên toàn thế giới vì sự rõ ràng, cẩn thận và các ví dụ lập trình chi tiết. Từ các nguyên tắc cơ bản của cú pháp Java đến các tính năng tiên tiến nhất của nó, Thinking in Java được thiết kế để dạy từng bước cho người lập trình từ bắt đầu đến các tính năng nâng cao.
Cuốn sách này cung cấp cách tiếp cận thực tế và từng bước để kiểm tra các ứng dụng về khả năng mở rộng (scalabiilty) và hiệu năng (performance ) trước khi chúng được triển khai lên môi trường production.
Tác giả: Ian Molyneaux
Go là một ngôn ngữ lập trình mới do Google thiết kế và phát triển. Nó được kỳ vọng sẽ giúp ngành công nghiệp phần mềm khai thác nền tảng đa lõi của bộ vi xử lý và hoạt động đa nhiệm tốt hơn
Đây là một cuốn sách cung cấp các giải pháp cho cấu trúc dữ liệu phức tạp và các thuật toán. Có nhiều giải pháp cho từng vấn đề và cuốn sách được trình bày với code C/C++, nó có ích cho bạn khi chuẩn bị kiến thức cho một cuộc phỏng vấn và hướng dẫn thi cử cho các nhà khoa học, kĩ sư trẻ.
Tên tài liệu : The Complete Reference C++ 4th Edition
Tác giả : Herbert Schildt
Số trang : 1058
Ngôn ngữ : Tiếng Anh
Format : PDF
Thể loại : C/C++ Programming
Tên tài liệu : Triển Khai Hệ Thống Mạng Windows Server 2012 Nâng Cao – 70-414
Tác giả : MCT Trần Thuỷ Hoàng
Số trang : 831
Ngôn ngữ : Tiếng Việt
Format : PDF
Thể loại : MCSE/Windows Server
Phiên bản : 1
Cuốn sách sẽ tạo ra một bước tiến lớn, đưa các thực tiễn tốt nhất hiện nay của phát triển web vào bài học, tập trung vào các ứng dụng lớn,… Bên cạnh đó còn giúp bạn tiếp cận các vấn đề khái niệm sâu sắc cần thiết cho lĩnh vực phát triển web.
Tên tài liệu : Giáo trình Javascript Tiếng Việt cơ bản
Tác giả : (tổng hợp)
Số trang : 3 cuốn ebook
Ngôn ngữ : Tiếng Việt
Format : PDF
Thể loại : Programming/Web/Javascript
Tên tài liệu : Tài liệu lập trình Java Spring MVC – ĐH FPT
Tác giả : ĐH FPT Polytechnic
Số ebook: 17
Ngôn ngữ : Tiếng Việt
Format : PDF
Thể loại : Programming/Java/Spring
Tên tài liệu : Mastering pfSense (PDF)
Tác giả : David Zientara
Số ebook: 406
Ngôn ngữ : Tiếng Anh
Format : PDF
Thể loại : SystemAdmin/Quản trị mạng
Giới thiệu mục lục ebook “Ma
Cuốn sách này được xem như tài liệu hướng dẫn từng bước cho Học Sinh – Sinh Viên của Trường trong việc học và áp dụng kiến thức lý thuyết trên lớp một cách thành thạo và sâu rộng.
Với ebook này bạn sẽ học lập trình C bằng cách thực hành thông qua 52 bài tập sáng tạo vô cùng tuyệt vời. Tập gõ mã code của tác giả một cách chính xác. Sau đó tập sửa lỗi của bạn. Xem cách chương trình chạy. Học cách làm thế nào để suy nghĩ hiệu quả hơn về mã code; làm thế nào để tìm và sửa chữa những lỗi hiệu quả hơn rất nhiều.
Nếu bạn muốn học tốt Java thì tuyệt đối không thể bỏ qua cuốn này. Thay vì yêu cầu bạn phải làm cái này hoặc cái kia, tác giả giải thích rất chi tiết tại sao bạn phải làm vấn đề đó. Nhờ đó, bạn sẽ nhớ kiến thức lâu hơn vì hiểu rõ tận gốc. Khá thú vị và hay ho phải không nào.
Hầu như những lập trình viên ngày nay đều có thể học nhanh và mới các ngôn ngữ lập trình hiện đại. Nhưng họ lại quên trau dồi các kĩ năng, kiến thức liên quan đến quá trình lập trình. Các kĩ năng lập trình này đều có thể áp dụng với tất cả mọi loại ngôn ngữ lập trình, giúp cải thiện tư duy cũng như năng lực cá nhân của bạn.






























































































.jpg)









